لم يتم العثور على نتائج
لا يمكننا العثور على أي شيء بهذا المصطلح في الوقت الحالي، حاول البحث عن شيء آخر.
حاسبة الـ z-score
تساعد حاسبة Z-Score في الحصول على Z-Score للتوزيع الطبيعي، والتحويل بين Z-Score والاحتمال، والحصول على الاحتمال بين اثنين z-scores.
| النتيجة | ||
|---|---|---|
| درجة Z | 1 | |
| احتمال x<5 | 0.84134 | |
| احتمال x>5 | 0.15866 | |
| احتمال 3<x<5 | 0.34134 | |
| النتيجة | ||
|---|---|---|
| درجة Z | 2 | |
| P(x<Z) | 0.97725 | |
| P(x>Z) | 0.02275 | |
| P(0<x<Z) | 0.47725 | |
| P(-Z<x<Z) | 0.9545 | |
| P(x<-Z or x>Z) | 0.0455 | |
| النتيجة | ||
|---|---|---|
| P(-1<x<0) | 0.34134 | |
| P(x<-1 or x>0) | 0.65866 | |
| P(x<-1) | 0.15866 | |
| P(x>0) | 0.5 | |
كان هناك خطأ في الحساب.
فهرس
- ما هو الـ Z-Score؟
- معادلة Z- Score
- تفسير نتائج الـ Z-Score التي تم الحصول عليها
- Z-Score والانحراف المعياري
- Z-Score والتوزيع الطبيعي
- مقارنة نقاط البيانات
- تطبيع البيانات
- اختبار الفرضيات
- ميزة التحجيم
- النمذجة التنبؤية
- استخدام جدول نقاط Z
- إيجاد الاحتمال من Z-Score
- إيجاد القيم المقابلة للاحتمالية المحددة

يمكن استخدام حاسبة Z-Score لأي نوع من الحسابات الذي يتطلب إيجاد الـ Z-Score. يمكنك إدخال النتيجة الأولية (X)، ومتوسط المجموعة (μ)، والانحراف المعياري (σ) في الآلة الحاسبة الأولى لإيجاد Z-Score بالخطوات والاحتمالات ذات الصلة لدرجة هذا الصف.
يساعدك محول Z-Score ومحول الاحتمالية على التحويل بين قيم الـ Z-Score والاحتمالات دون الرجوع إلى جدول Z. ستشمل النتائج جميع حسابات الاحتمالات الممكنة بهذه الـ Z-Score المفردة. استخدم الآلة الحاسبة الأخيرة لإيجاد الاحتمال بين درجتين Z-Score.
ما هو الـ Z-Score؟
Z-Score عبارة عن مقياس إحصائي يصف عدد الانحرافات المعيارية لنقطة بيانات عن متوسط مجموعة بيانات. تُستخدم الـ Z-Score لمقارنة نقطة بيانات واحدة بمجموعة البيانات بأكملها وتساعد على توحيد البيانات بحيث يسهل المقارنة والتحليل.
يسمح لنا الـ Z-Score بتحديد كيفية مقارنة نقطة بيانات واحدة "نموذجية" أو "غير نمطية" بالعكس بمجموعة البيانات بأكملها.
- اكتشاف القيم المتطرفة: يمكن أن تساعدنا Z-Score في تحديد نقاط البيانات التي تختلف اختلافًا كبيرًا عن بقية البيانات. هذا مفيد في مجالات مثل التمويل والبحوث الطبية، حيث يمكن أن تشير القيم المتطرفة إلى أنماط مهمة أو شذوذ.
- مقارنة البيانات من مجموعات مختلفة: تسمح لنا Z-Score بمقارنة البيانات من مجموعات مختلفة، حتى لو كانت تحتوي على وحدات أو نطاقات مختلفة. هذا مفيد في مجالات مثل التعلم الآلي، حيث تحتاج إلى مقارنة البيانات من مصادر مختلفة لبناء النماذج.
- تطبيع البيانات: من خلال تحويل البيانات إلى Z-Score، يمكننا توحيد البيانات وتسهيل المقارنة والتحليل. هذا مفيد في مجالات مثل تصور البيانات، حيث نحتاج إلى تقديم البيانات بطريقة مفهومة.
معادلة Z- Score
الـ Z-Score لمجموعة من فصيل واحد
Z= الدرجة الأولية - متوسط المجموعة / الانحراف المعياري للمجموعة
Z = (X - μ) / σ
الـ Z-Score لعينة ما
Z= الدرجة الأولية - متوسط العينة / عينة الانحراف المعياري
Z = (X - x̄) / s
تفسير نتائج الـ Z-Score التي تم الحصول عليها
عندما يكون الـ Z-Score بالموجب: تعني أن نقطة البيانات الخاصة بك أعلى من متوسط قيمة مجموعة البيانات. بعبارة أخرى، تكون نقطة البيانات التي تمت ملاحظتها أعلى من القيمة النموذجية في مجموعة البيانات.
عندما يكون الـ Z-Score بالسالب: تعنى أن نقطة البيانات الخاصة بك أقل من متوسط قيمة مجموعة البيانات. بمعنى آخر، تكون نقطة البيانات التي تمت ملاحظتها أقل من القيمة النموذجية في مجموعة البيانات.
يخبرك Z-Score: بمدى بُعد نقطة بياناتك عن متوسط مجموعة البيانات. كلما زادت Z-Score، كلما كانت نقطة البيانات التي تمت ملاحظتها أبعد من القيمة المتوسطة.
Z-Score والانحراف المعياري
ترتبط Z-Score والانحراف المعياري لأنه يتم استخدام الانحراف المعياري لحساب Z-Score. في الواقع، يعد الانحراف المعياري مكونًا رئيسيًا في معادلة Z-Score.
الانحراف المعياري هو مقياس انتشار مجموعة البيانات. يُظهر مدى بُعد كل نقطة بيانات عن متوسط قيمة مجموعة البيانات. كلما زاد الانحراف المعياري، زاد تشتت البيانات.
من ناحية أخرى، يخبرك Z-Score بمدى بُعد نقطة بيانات واحدة عن متوسط مجموعة البيانات بالنسبة إلى الانحراف المعياري. باستخدام الانحراف المعياري لحساب Z-Score، يمكنك مقارنة نقطة بيانات واحدة بمجموعة البيانات بأكملها ومعرفة مدى كونها غير عادية أو نموذجية.
Z-Score والتوزيع الطبيعي
التوزيع الطبيعي هو نوع من التوزيع يوجد غالبًا في العديد من ظواهر العالم الحقيقي. إنه منحنى على شكل جرس يمثل توزيع البيانات حول متوسط مجموعة من البيانات. يُعرف التوزيع الطبيعي أيضًا باسم التوزيع الغاوسي، بعد عالم الرياضيات كارل فريدريش جاوس.
Z-Score هي طريقة لقياس مدى بُعد نقطة بيانات واحدة عن متوسط مجموعة البيانات بالنسبة إلى الانحراف المعياري. من خلال تحويل كل نقطة بيانات إلى Z-Score، يمكنك مقارنة نقطة بيانات فردية بمجموعة البيانات بأكملها ومعرفة مدى كونها غير عادية أو نموذجية.
الاتصال بين Z-Score والتوزيع العادي هو أنه يمكن استخدام Z-Score لتوحيد البيانات ومطابقتها للتوزيع العادي. هذا يعني أنه يمكنك تحويل أي مجموعة بيانات إلى توزيع عادي عن طريق تحويل كل نقطة بيانات إلى Z-Score. هذا مفيد لأن العديد من الأساليب الإحصائية تفترض أن البيانات يتم توزيعها بشكل طبيعي، لذا فإن تحويل البيانات إلى توزيع عادي يمكن أن يساعدك في استخدام هذه الطرق بشكل أكثر دقة.
مقارنة نقاط البيانات
يمكن أن يساعدك Z-Score في فهم مدى بُعد نقطة بيانات واحدة عن متوسط مجموعة بيانات بالنسبة إلى الانحراف المعياري.
ينطبق مثالنا على استخدام Z-Score لمقارنة نقاط البيانات على التمويل. على سبيل المثال، لقد استثمرت في محفظتين مختلفتين للأوراق المالية وتريد مقارنة أدائهما. متوسط عائد المحفظة (أ) هو 10% بانحراف معياري 2%، ومتوسط عائد المحفظة (ب) هو 8% بانحراف معياري 3%. من خلال تحويل العوائد إلى Z-scores، يمكنك مقارنة عوائد كل محفظة وتحديد أيها يحقق أداءً أفضل.
مثال عملي آخر على استخدام Z-Score لمقارنة نقاط البيانات هو الرياضة. على سبيل المثال، تريد مقارنة أداء لاعبي كرة سلة، اللاعب "أ" واللاعب "ب". يسجل اللاعب "أ" في المتوسط 20 نقطة في كل لعبة بانحراف معياري قدره 5 نقاط، ويحصل اللاعب "ب" على معدل 18 نقطة في كل لعبة لمدة الانحراف المعياري بمقدار 3 نقاط. من خلال تحويل الدرجات إلى Z-Score، يمكنك مقارنة أداء كل لاعب وتحديد اللاعب الأفضل أداءً.
تطبيع البيانات
تطبيع البيانات هو عملية تحويل البيانات إلى مقياس قياسي بحيث يمكن مقارنتها وتحليلها بسهولة. هذا مهم لأن البيانات يمكن أن يكون لها أشكال ومقاييس مختلفة، وتضمن تسوية البيانات أن تكون على نفس المقياس وتسهل المقارنة والتحليل.
بتحويل كل نقطة بيانات إلى Z-Score، يمكنك توحيد البيانات ووضعها على نفس المقياس. هذا لأن Z-Score تكون دائمًا على مقياس قياسي، حيث يكون المتوسط 0 والانحراف المعياري هو 1.
أحد الأمثلة العملية على استخدام Z-Score لتطبيع البيانات يتعلق بمجال علم النفس. على سبيل المثال، تريد مقارنة نتائج اختبارين من اختبارات الذكاء، الاختبار أ والاختبار ب، الاختبار أ بمتوسط 100 درجة مع انحراف معياري قدره 15، والاختبار ب لديه متوسط درجة 110 مع انحراف معياري قدره 10 من خلال تحويل الدرجات إلى Z-Score، يمكن توحيد الدرجات وتقليلها إلى مقياس واحد، مما يسهل المقارنة والتحليل.
مثال عملي آخر على استخدام Z-Score لتطبيع البيانات في التعليم. على سبيل المثال، تريد مقارنة درجات طالبين، الطالب "أ" والطالب "ب". يحصل الطالب "أ" على متوسط درجة 80 بانحراف معياري 5، بينما يحصل الطالب "ب" على درجة متوسطة تبلغ 90 مع انحراف معياري قدره 3. بتحويل الدرجات إلى Z-sore، يمكنك توحيد الدرجات وجعلها جميعًا على نفس المقياس، مما يجعل المقارنة والتحليل أسهل.
اختبار الفرضيات
اختبار الفرضيات هو أسلوب إحصائي يستخدم لتحديد ما إذا كان هناك دليل كاف لرفض الفرضية الصفرية، أو الافتراض القياسي بعدم وجود علاقة بين متغيرين. إنه مهم في العديد من المجالات، بما في ذلك البحث الطبي والعلوم الاجتماعية والأعمال، حيث يكون اتخاذ قرارات مستنيرة بناءً على البيانات أمرًا بالغ الأهمية.
عند اختبار الفرضيات، يمكن استخدام معاملات Z لتحديد احتمال حدوث نتيجة معينة. على سبيل المثال، يمكنك اختبار ما إذا كان متوسط وزن مجموعة من الأشخاص يختلف عن متوسط وزن المجموعة بأكملها. يمكنك استخدام Z-Score لتحديد ما إذا كان الاختلاف ذا دلالة إحصائية.
أحد الأمثلة العملية على استخدام Z-Score لاختبار الفرضيات هو في المجال الطبي. على سبيل المثال، تريد اختبار ما إذا كان دواء جديد فعالًا في تقليل أعراض مرض معين. يمكنك استخدام Z-Score لتحديد ما إذا كان الاختلاف في الأعراض بين المجموعة التي تتناول الدواء والمجموعة الضابطة ذو دلالة إحصائية.
مثال عملي آخر على استخدام Z-Score لاختبار الفرضيات في مجال التمويل. على سبيل المثال، تريد اختبار ما إذا كان سهم معين لديه عائد أعلى من متوسط المخزون في السوق. يمكنك استخدام Z-Score لتحديد ما إذا كان الفرق في العوائد ذو دلالة إحصائية.
ميزة التحجيم
تحجيم الميزة هو أسلوب يستخدم في التعلم الآلي وتطبيقات تحليل البيانات الأخرى لضمان أن جميع الميزات في مجموعة البيانات لها نفس المقياس. هذا مهم لأن بعض خوارزميات التعلم الآلي حساسة لمقياس البيانات ويمكن أن تنتج نتائج غير دقيقة إذا لم يتطابق المقياس.
إحدى الطرق الشائعة لقياس السمات هي تطبيع Z-Score، والمعروف أيضًا باسم التوحيد. في هذه العملية، يتم تحويل كل سمة بحيث يكون متوسط قيمتها 0 وانحرافها المعياري هو 1. معادلة حساب الـ Z-Score للسمة هي كما يلي:
Z = (X – المتوسط) / الانحراف المعياري
حيث X هي قيمة الميزة، والمتوسط هو متوسط الميزة، والانحراف المعياري هو الانحراف المعياري للميزة.
مثال عملي لاستخدام Z-Score لتوسيع نطاق الميزات في مجال رؤية الكمبيوتر. عند العمل مع بيانات الصورة، يُطلب عادةً قياس قيم البكسل بحيث تكون في النطاق من 0 إلى 1. ويمكن تحقيق ذلك عن طريق تسوية Z-Score، حيث يمكن تحويل كل قيمة بكسل بحيث تكون قيمتها المتوسطة 0، وانحرافه المعياري هو 1.
مثال عملي آخر على استخدام Z-score لتوسيع نطاق الميزات هو معالجة اللغة الطبيعية. عند العمل مع البيانات النصية، من الشائع قياس قيم تكرار المصطلح وتردد المستند العكسي (TF-IDF) بحيث تكون في النطاق من 0 إلى 1. ويمكن تحقيق ذلك أيضًا باستخدام تسوية Z-Score.
النمذجة التنبؤية
النمذجة التنبؤية هي تقنية مستخدمة في التعلم الآلي وتطبيقات تحليل البيانات الأخرى لعمل تنبؤات تستند إلى البيانات التاريخية. يتضمن تدريب نموذج على مجموعة بيانات واستخدام هذا النموذج لعمل تنبؤات بشأن بيانات جديدة غير مرئية.
أحد الجوانب المهمة للنمذجة التنبؤية هو اختيار الميزة، والذي يتضمن اختيار الميزات الأكثر صلة من مجموعة البيانات لاستخدامها في النموذج. في كثير من الأحيان، تُفضل السمات التي ترتبط ارتباطًا وثيقًا بالمتغير المستهدف لأنها من المرجح أن تتنبأ بالمتغير المستهدف.
يمكن استخدام Z-Score لتحديد السمات التي ترتبط ارتباطًا وثيقًا بالمتغير المستهدف لأن الصفات التي تحتوي على Z-Score عالية من المرجح أن تتنبأ بالمتغير المستهدف. معادلة حساب الـ Z-Score للسمة هي كما يلي:
Z = (X - المتوسط) / الانحراف المعياري
حيث X هي قيمة الميزة، والمتوسط هو متوسط الميزة، والانحراف المعياري هو الانحراف المعياري للميزة.
مثال عملي لاستخدام Z-Score في النمذجة النذير ينتمي إلى مجال التمويل. عند التنبؤ بأسعار الأسهم، يمكن استخدام Z-Score للأداء السابق للسهم لتحديد عائده المحتمل في المستقبل. تشير Z-Score العالية إلى أن العائد السابق للسهم أعلى بكثير من المتوسط ويمكن توقع عوائد أعلى في المستقبل.
مثال عملي آخر على استخدام Z-Score في النمذجة التنبؤية في مجال الرعاية الصحية. عند التنبؤ بنتائج المريض، يمكن استخدام Z-Score لتحديد إمكانات المريض للنتائج المستقبلية. تشير Z-Score العالية إلى أن النتائج الصحية للمريض أسوأ بكثير من المتوسط وقد تشير إلى نتائج مستقبلية سيئة.
استخدام جدول نقاط Z
جدول z، المعروف أيضًا باسم الجدول العادي القياسي أو الجدول العادي للوحدة، هو جدول يحتوي على قيم معيارية تُستخدم لحساب احتمالية إحصائية معينة تقع أسفل أو أعلى أو بين التوزيع العادي القياسي.
| z | 0 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.00399 | 0.00798 | 0.01197 | 0.01595 | 0.01994 | 0.02392 | 0.0279 | 0.03188 | 0.03586 |
| 0.1 | 0.03983 | 0.0438 | 0.04776 | 0.05172 | 0.05567 | 0.05962 | 0.06356 | 0.06749 | 0.07142 | 0.07535 |
| 0.2 | 0.07926 | 0.08317 | 0.08706 | 0.09095 | 0.09483 | 0.09871 | 0.10257 | 0.10642 | 0.11026 | 0.11409 |
| 0.3 | 0.11791 | 0.12172 | 0.12552 | 0.1293 | 0.13307 | 0.13683 | 0.14058 | 0.14431 | 0.14803 | 0.15173 |
| 0.4 | 0.15542 | 0.1591 | 0.16276 | 0.1664 | 0.17003 | 0.17364 | 0.17724 | 0.18082 | 0.18439 | 0.18793 |
| 0.5 | 0.19146 | 0.19497 | 0.19847 | 0.20194 | 0.2054 | 0.20884 | 0.21226 | 0.21566 | 0.21904 | 0.2224 |
| 0.6 | 0.22575 | 0.22907 | 0.23237 | 0.23565 | 0.23891 | 0.24215 | 0.24537 | 0.24857 | 0.25175 | 0.2549 |
| 0.7 | 0.25804 | 0.26115 | 0.26424 | 0.2673 | 0.27035 | 0.27337 | 0.27637 | 0.27935 | 0.2823 | 0.28524 |
| 0.8 | 0.28814 | 0.29103 | 0.29389 | 0.29673 | 0.29955 | 0.30234 | 0.30511 | 0.30785 | 0.31057 | 0.31327 |
| 0.9 | 0.31594 | 0.31859 | 0.32121 | 0.32381 | 0.32639 | 0.32894 | 0.33147 | 0.33398 | 0.33646 | 0.33891 |
| 1 | 0.34134 | 0.34375 | 0.34614 | 0.34849 | 0.35083 | 0.35314 | 0.35543 | 0.35769 | 0.35993 | 0.36214 |
| 1.1 | 0.36433 | 0.3665 | 0.36864 | 0.37076 | 0.37286 | 0.37493 | 0.37698 | 0.379 | 0.381 | 0.38298 |
| 1.2 | 0.38493 | 0.38686 | 0.38877 | 0.39065 | 0.39251 | 0.39435 | 0.39617 | 0.39796 | 0.39973 | 0.40147 |
| 1.3 | 0.4032 | 0.4049 | 0.40658 | 0.40824 | 0.40988 | 0.41149 | 0.41308 | 0.41466 | 0.41621 | 0.41774 |
| 1.4 | 0.41924 | 0.42073 | 0.4222 | 0.42364 | 0.42507 | 0.42647 | 0.42785 | 0.42922 | 0.43056 | 0.43189 |
| 1.5 | 0.43319 | 0.43448 | 0.43574 | 0.43699 | 0.43822 | 0.43943 | 0.44062 | 0.44179 | 0.44295 | 0.44408 |
| 1.6 | 0.4452 | 0.4463 | 0.44738 | 0.44845 | 0.4495 | 0.45053 | 0.45154 | 0.45254 | 0.45352 | 0.45449 |
| 1.7 | 0.45543 | 0.45637 | 0.45728 | 0.45818 | 0.45907 | 0.45994 | 0.4608 | 0.46164 | 0.46246 | 0.46327 |
| 1.8 | 0.46407 | 0.46485 | 0.46562 | 0.46638 | 0.46712 | 0.46784 | 0.46856 | 0.46926 | 0.46995 | 0.47062 |
| 1.9 | 0.47128 | 0.47193 | 0.47257 | 0.4732 | 0.47381 | 0.47441 | 0.475 | 0.47558 | 0.47615 | 0.4767 |
| 2 | 0.47725 | 0.47778 | 0.47831 | 0.47882 | 0.47932 | 0.47982 | 0.4803 | 0.48077 | 0.48124 | 0.48169 |
| 2.1 | 0.48214 | 0.48257 | 0.483 | 0.48341 | 0.48382 | 0.48422 | 0.48461 | 0.485 | 0.48537 | 0.48574 |
| 2.2 | 0.4861 | 0.48645 | 0.48679 | 0.48713 | 0.48745 | 0.48778 | 0.48809 | 0.4884 | 0.4887 | 0.48899 |
| 2.3 | 0.48928 | 0.48956 | 0.48983 | 0.4901 | 0.49036 | 0.49061 | 0.49086 | 0.49111 | 0.49134 | 0.49158 |
| 2.4 | 0.4918 | 0.49202 | 0.49224 | 0.49245 | 0.49266 | 0.49286 | 0.49305 | 0.49324 | 0.49343 | 0.49361 |
| 2.5 | 0.49379 | 0.49396 | 0.49413 | 0.4943 | 0.49446 | 0.49461 | 0.49477 | 0.49492 | 0.49506 | 0.4952 |
| 2.6 | 0.49534 | 0.49547 | 0.4956 | 0.49573 | 0.49585 | 0.49598 | 0.49609 | 0.49621 | 0.49632 | 0.49643 |
| 2.7 | 0.49653 | 0.49664 | 0.49674 | 0.49683 | 0.49693 | 0.49702 | 0.49711 | 0.4972 | 0.49728 | 0.49736 |
| 2.8 | 0.49744 | 0.49752 | 0.4976 | 0.49767 | 0.49774 | 0.49781 | 0.49788 | 0.49795 | 0.49801 | 0.49807 |
| 2.9 | 0.49813 | 0.49819 | 0.49825 | 0.49831 | 0.49836 | 0.49841 | 0.49846 | 0.49851 | 0.49856 | 0.49861 |
| 3 | 0.49865 | 0.49869 | 0.49874 | 0.49878 | 0.49882 | 0.49886 | 0.49889 | 0.49893 | 0.49896 | 0.499 |
| 3.1 | 0.49903 | 0.49906 | 0.4991 | 0.49913 | 0.49916 | 0.49918 | 0.49921 | 0.49924 | 0.49926 | 0.49929 |
| 3.2 | 0.49931 | 0.49934 | 0.49936 | 0.49938 | 0.4994 | 0.49942 | 0.49944 | 0.49946 | 0.49948 | 0.4995 |
| 3.3 | 0.49952 | 0.49953 | 0.49955 | 0.49957 | 0.49958 | 0.4996 | 0.49961 | 0.49962 | 0.49964 | 0.49965 |
| 3.4 | 0.49966 | 0.49968 | 0.49969 | 0.4997 | 0.49971 | 0.49972 | 0.49973 | 0.49974 | 0.49975 | 0.49976 |
| 3.5 | 0.49977 | 0.49978 | 0.49978 | 0.49979 | 0.4998 | 0.49981 | 0.49981 | 0.49982 | 0.49983 | 0.49983 |
| 3.6 | 0.49984 | 0.49985 | 0.49985 | 0.49986 | 0.49986 | 0.49987 | 0.49987 | 0.49988 | 0.49988 | 0.49989 |
| 3.7 | 0.49989 | 0.4999 | 0.4999 | 0.4999 | 0.49991 | 0.49991 | 0.49992 | 0.49992 | 0.49992 | 0.49992 |
| 3.8 | 0.49993 | 0.49993 | 0.49993 | 0.49994 | 0.49994 | 0.49994 | 0.49994 | 0.49995 | 0.49995 | 0.49995 |
| 3.9 | 0.49995 | 0.49995 | 0.49996 | 0.49996 | 0.49996 | 0.49996 | 0.49996 | 0.49996 | 0.49997 | 0.49997 |
| 4 | 0.49997 | 0.49997 | 0.49997 | 0.49997 | 0.49997 | 0.49997 | 0.49998 | 0.49998 | 0.49998 | 0.49998 |
لاستخدام جدول z، تحتاج إلى إيجاد الصف الذي يتوافق مع Z-Score المحسوبة ثم تحديد العمود المقابل الذي يمنحك المنطقة (الاحتمال) أسفل المنحنى القياسي. القيمة الناتجة هي الاحتمال التقريبي بأن يكون المتغير العشوائي من التوزيع العادي القياسي أقل من أو يساوي Z-Score المحسوبة.
على سبيل المثال، إذا كان لديك Z-Score 1.96، فستبحث في جدول z عن الصف المقابل لـ 1.9 والعمود الذي يقابل 0.06. ستمنحك القيمة الناتجة المساحة الواقعة أسفل المنحنى العادي القياسي على يمين 1.96. هذه القيمة تقارب 0.975، مما يعني أن حوالي 97.5% من البيانات من التوزيع الطبيعي القياسي ستكون أقل من أو تساوي 1.96.
من المهم ملاحظة أن جدول z يعمل فقط للتوزيع العادي القياسي بمتوسط 0 وانحراف معياري قدره 1. إذا كانت بياناتك لا تتبع هذا التوزيع، فستحتاج إلى توحيدها أولاً عن طريق تحويل البيانات إلى z -درجات.
إيجاد الاحتمال من Z-Score
عندما نحول متغيرًا موزعًا بشكل طبيعي إلى Z-Score، يمكننا استخدام جدول Z-Score وإيجاد نسبة المساحة تحت المنحنى العادي. إجمالي المساحة تحت المنحنى العادي القياسي يساوي 1. لذلك، فإن نسبة المساحة التي يغطيها المنحنى العادي تساوي احتمال Z-Score.
مثال 1
توزع أوزان لاعبي الملاكمة عادة بمتوسط 75 كجم وانحراف معياري 3 كجم. ما هو احتمال أن يكون وزن اللاعب المختار عشوائيًا؛
- أ) أكثر من 78 كجم؟
- ب) أقل من 69 كجم؟
- ج) أكثر من 72 كجم؟
- د) أقل من 79.5 كجم؟
- ه) بين 72 كجم و 76.5 كجم؟
- و) بين 72 كجم و 73.5 كجم؟
أ) ما هو احتمال أن يزن لاعب تم اختياره عشوائيًا أكثر من 78 كجم؟
- X > 78
- μ = 75
- σ = 3
$$P(X>78)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{78-75}{3}\right)=P(Z>1)$$
أولاً، سنرسم هذا في منحنى Z.
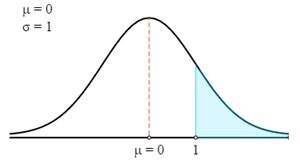
الآن سوف نستخدم Z-Table لإيجاد على الاحتمال ذي الصلة لـ Z-Score المحسوبة.
تذكر أن Z-Score تعطي دائمًا الاحتمال بين Z-Score والمتوسط. للحصول على احتمال المنطقة المظللة في الرسم البياني، نحتاج إلى تقليل هذا الاحتمال من 0.5. (إجمالي الاحتمال تحت المنحنى هو 1، ومتوسط التوزيع القياسي ينقسم بالتساوي إلى جزأين. وبالتالي، فإن الاحتمال من النقطة المتوسطة إلى أي من جانبي النهاية هو 0.5.)
- P (X > 78) = P (Z > 1)
- P (X > 78) = 0.5 - P(0 < Z < 1)
- P (X > 78) = 0.5 - 0.3413
- P (X > 78) = 0.1587
لذلك، هناك احتمال 0.1587 أن يزيد وزن لاعب تم اختياره عشوائيًا عن 78 كجم.
ب) ما هو احتمال أن يزن لاعب تم اختياره عشوائيًا أقل من 69 كجم؟
- X < 69
- μ = 75
- σ = 3
$$P(X<69)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{69-75}{3}\right)=P(Z<-2)$$
أولاً، سنرسم هذا في منحنى Z.
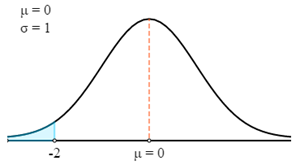
الآن سوف نستخدم Z-Table لإيجاد على الاحتمال ذي الصلة ل Z-Score المحسوبة.
تذكر أن Z-Score تعطي دائمًا الاحتمال بين Z-Score والمتوسط. للحصول على احتمال المنطقة المظللة في الرسم البياني، نحتاج إلى تقليل هذا الاحتمال من 0.5
- P (X < 69) = P (Z < 69)
- P (X < 69) = 0.5 - P (0 > Z > -2)
- P (X < 69) = 0.5 - 0.4772
- P (X < 69) = 0.0228
لذلك، هناك احتمال 0.0228 أن يكون وزن اللاعب المختار عشوائيًا أقل من 69 كجم.
ج) ما هو احتمال أن يتراوح وزن لاعب تم اختياره عشوائيًا بين 72 كجم و76.5 كجم؟
- 72 < X < 76.5
- μ = 75
- σ = 3
$$P(72 \lt X \lt 76.5)=P\left(\frac{X-μ}{σ} \lt Z \lt \frac{X-μ}{σ}\right)=P\left(\frac{72-75}{3} \lt Z \lt \frac{76.5-75}{3}\right)=P(-1 \lt Z \lt 0.5)$$
أولاً، سنرسم هذا في منحنى Z.
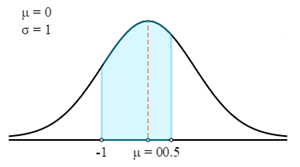
الآن سوف نستخدم Z-Table لإيجاد على الاحتمال ذي الصلة لـ Z-Score المحسوبة.
تذكر أن Z-Score تعطي دائمًا الاحتمال بين Z-Score والمتوسط. للحصول على احتمالية المنطقة المظللة في الرسم البياني، يمكنك جمع احتمالات Z-Score الاثنين معًا.
- P (72 < X < 76.5) = P (-1 < Z < 0.5)
- P (72 < X < 76.5) = 0.3413 + 0.1915
- P (72 < X < 76.5) = 0.5328
لذلك، هناك احتمال 0.5328 أن يتراوح وزن اللاعب المختار عشوائيًا بين 72 كجم و76.5 كجم.
في هذه الحالة، يجب عليك استخدام حاسبة الاحتمال بين درجتين Z لإيجاد على الإجابة بسرعة.
إيجاد القيم المقابلة للاحتمالية المحددة
عندما نعلم أن التوزيع طبيعي، يمكننا العثور على القيم المقابلة للاحتمالات المحددة بناءً على Z-Score.
مثال 2
يتم توزيع علامات المتقدمين في الاختبار التنافسي بشكل طبيعي تقريبًا، بمتوسط 55 وانحراف معياري 10. إذا نجح أعلى 30% من المتقدمين في الاختبار، فابحث عن الحد الأدنى لدرجة النجاح.
الحل
في هذه الحالة، يتعين علينا أولاً إيجاد Z-Score المقابلة للاحتمال أو النسبة المئوية المحددة.
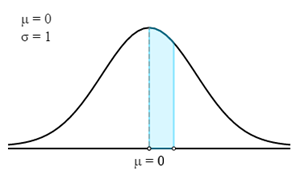
لإيجاد Z-Score، نحتاج بالفعل إلى إيجاد الاحتمال في المنطقة المظللة.
يتم الحصول عليها بخصم 0.30 من 0.50 لذلك، فإن احتمال المنطقة المظللة هو 0.20
الآن، في الجدول Z، علينا إيجاد أقرب احتمال لـ 0.20. Z-Score المقابلة هي 0.524
بعد ذلك، يتعين علينا إيجاد قيمة X باستخدام معادلة Z-Score.
- Z = (X - μ)/σ
- 0.524 = (X - 55)/10
- X = (0.524 × 10) + 55
- X = 60.24
لذلك، فإن الحد الأدنى لدرجة النجاح في الامتحان هو 60.24