Aucun résultat trouvé
Nous ne pouvons rien trouver avec ce terme pour le moment, essayez de chercher autre chose.
Calculatrice de score z
La calculatrice de score z permet de trouver le score z d'une distribution normale, de convertir entre eux le score z et la probabilité ainsi que d'obtenir la probabilité entre 2 scores z.
| Résultat | ||
|---|---|---|
| Score Z | 1 | |
| Probabilité de x<5 | 0.84134 | |
| Probabilité de x>5 | 0.15866 | |
| Probabilité de 3<x<5 | 0.34134 | |
| Résultat | ||
|---|---|---|
| Score Z | 2 | |
| P(x<Z) | 0.97725 | |
| P(x>Z) | 0.02275 | |
| P(0<x<Z) | 0.47725 | |
| P(-Z<x<Z) | 0.9545 | |
| P(x<-Z or x>Z) | 0.0455 | |
| Résultat | ||
|---|---|---|
| P(-1<x<0) | 0.34134 | |
| P(x<-1 or x>0) | 0.65866 | |
| P(x<-1) | 0.15866 | |
| P(x>0) | 0.5 | |
Il y avait une erreur avec votre calcul.
Table des Matières
- Qu'est-ce qu'un score z ?
- La formule du score z
- Interprétation des résultats du score z obtenu
- Score z et écart-type
- Le score z et la distribution normale
- Comparaison des points de données
- Normalisation des données
- Test d'hypothèse
- Mise à l'échelle des caractéristiques
- Modélisation prévisionnelle
- Utilisation de la table des scores z
- Trouver la probabilité à partir du score z
- Trouver les valeurs correspondant à une probabilité déterminée

On peut utiliser la calculatrice de score z pour toutes les sortes de calculs liées au score z. On peut saisir un score brut (X), une moyenne de population (μ) et un écart-type (σ) dans la première calculatrice afin de trouver le score z avec les étapes et les probabilités associées à ce score brut.
Le convertisseur de score z et de probabilité vous aide à convertir les scores z et les probabilités entre eux sans avoir à consulter une table z. Les résultats incluront tous les calculs de probabilité qui sont possibles avec ce seul score z. On se sert de la deuxième calculatrice pour trouver la probabilité entre 2 scores z.
Qu'est-ce qu'un score z ?
Un score z est une mesure statistique qui décrit le nombre d'écarts-types qu'il y a d'un point de donnée à la moyenne d'une série de données. Le score z sert à comparer un seul point de donnée à l'ensemble des données et il permet d'homogénéiser les données afin qu'elles soient plus faciles à comparer et à analyser.
Le score z va nous permettre de déterminer dans quelle mesure un point de donnée est représentatif de l'ensemble des données ou, inversement, dans quelle mesure il diffère de l'ensemble des données.
- Détecter les valeurs aberrantes : les scores z peuvent nous aider à identifier les points de données qui sont considérablement différents du reste des données. C'est important dans des domaines où les valeurs aberrantes peuvent indiquer des schémas ou des anomalies essentielles, tels que la finance et la recherche médicale.
- Comparer les données de différentes séries : le score z nous permet de comparer les données de différentes séries, même si leurs unités ou leurs intervalles sont différents. C'est très utile dans des domaines tels que l'apprentissage automatique, un domaine où vous devez comparer les données de sources différentes pour construire des modèles.
- Normaliser les données : en convertissant les données en scores z, nous pouvons homogénéiser les données et faciliter la comparaison et l'analyse. C'est très utile dans des domaines tels que la visualisation de données où nous devons présenter les données de manière compréhensible.
La formule du score z
Le score z pour une population
Z = (score brut - moyenne de la population)/écart-type de la population
Z = (X - μ)/σ
Le score z pour un échantillon
Z = (score brut - moyenne de l'échantillon)/écart-type de l'échantillon
Z = (X - x̄)/s
Interprétation des résultats du score z obtenu
Score z positif : un score z positif signifie que votre point de donnée est supérieur à la valeur moyenne de la série de données. En d'autres termes, le point de donnée que vous examinez est au-dessus de la valeur représentative de la série de données.
Score z négatif : un score z négatif signifie que votre point de donnée est inférieur à la valeur moyenne de la série de données. En d'autres termes, le point de donnée que vous examinez est en-dessous de la valeur représentative de la série de données.
Score z : le score z vous indique à quel point votre point de donnée et la moyenne de la série de données sont éloignés l'un de l'autre. Plus le score z est grand, plus le point de donnée examiné est éloigné de la valeur moyenne.
Score z et écart-type
Le score z et l'écart-type sont liés parce qu'on utilise l'écart-type pour calculer le score z. En fait, l'écart-type est un élément essentiel de la formule du score z.
L'écart-type est une mesure de l'écartement de la série de données. Il indique l'éloignement entre chaque point de donnée et la valeur moyenne de la série de données. Plus l'écart-type est important, plus les données sont dispersées.
Le score z, quant à lui, vous indique l'éloignement entre un point de donnée et la moyenne de la série de données par rapport à l'écart-type. En utilisant l'écart-type pour calculer le score z, vous pouvez comparer un point de donnée à l'ensemble des données et déterminer s'il est inhabituel ou représentatif.
Le score z et la distribution normale
On retrouve la distribution normale dans de nombreux phénomènes du monde réel. C'est une courbe en forme de cloche qui représente la distribution des données autour de la moyenne d'une série de données. La distribution normale est également connue sous le nom de distribution gaussienne, d'après le mathématicien Carl Friedrich Gauss.
Le score z est un moyen de mesurer l'éloignement entre un point de donnée et la moyenne d'une série de données par rapport à l'écart-type. En convertissant chaque point de donnée en score z, vous pouvez comparer un point de donnée individuel à l'ensemble des données et déterminer s'il est inhabituel ou représentatif.
Le lien entre un score z et une distribution normale repose sur le fait qu'on peut utiliser le score z pour homogénéiser les données et les rendre conformes à une distribution normale. Cela signifie que vous pouvez transformer n'importe quelle série de données en distribution normale en convertissant chaque point de donnée en score z. C'est très utile parce que de nombreuses méthodes statistiques supposent que les données sont distribuées normalement et, donc, convertir les données en distribution normale vous aidera certainement à utiliser ces méthodes avec plus de précision.
Comparaison des points de données
Le score z peut vous aider à déterminer si un point de donnée est éloigné de la moyenne d'une série de données par rapport à l'écart-type.
Nous allons voir un exemple d'utilisation du score z pour comparer des points de données qui s'applique à la finance. Par exemple, vous avez investi dans deux portefeuilles d'actions différents et souhaitez comparer leurs performances. Le rendement moyen du portefeuille A est de 10 % avec un écart-type de 2 % et le rendement moyen du portefeuille B est de 8 % avec un écart-type de 3 %. Si vous transformez les rendements en scores z, vous pouvez comparer les rendements de chaque portefeuille et déterminer lequel est le plus performant.
Le sport est un autre exemple pratique d'utilisation du score z pour comparer des points de données. Par exemple, vous voulez comparer les performances de deux joueurs de basket-ball, le joueur A et le joueur B. Le joueur A marque en moyenne 20 points par match pour un écart-type de 5 points et le joueur B marque en moyenne 18 points par match pour un écart-type de 3 points. En convertissant les scores en scores z, vous pouvez comparer les performances de chaque joueur et déterminer quel est le joueur le plus performant.
Normalisation des données
La normalisation des données c'est quand les données sont converties à une échelle standard afin d'être facilement comparées et analysées. C'est important car les données peuvent avoir des formes ainsi que des échelles différentes, et la normalisation des données garantit qu'elles soient à la même échelle tout en facilitant la comparaison et l'analyse.
En convertissant chaque point de donnée en score z, vous pouvez homogénéiser les données et les mettre à la même échelle. En effet, le score z est toujours à une échelle standard, à laquelle la moyenne est égale à 0 et l'écart-type est égal à 1.
Un exemple pratique d'utilisation du score z pour normaliser les données concerne le domaine de la psychologie. Par exemple, vous voulez comparer les résultats de deux tests de QI, le test A et le test B. Le score moyen du test A est de 100 avec un écart-type de 15 et le score moyen du test B est de 110 avec un écart-type de 10. En convertissant les scores en scores z, ils peuvent être homogénéisés et résumés à une seule échelle, ce qui facilite la comparaison et l'analyse.
L'éducation représente un autre exemple pratique de l'utilisation du score z pour normaliser les données. Par exemple, vous voulez comparer les notes de deux étudiants, l'étudiant A et l'étudiant B. L'étudiant A a une moyenne de 80 avec un écart-type de 5 et l'étudiant B a une moyenne de 90 avec un écart-type de 3. En convertissant les notes en coefficients z, vous pouvez homogénéiser les notes et toutes les mettre à la même échelle, ce qui facilite la comparaison et l'analyse.
Test d'hypothèse
Le test d'hypothèse est une technique de statistique qu'on utilise afin de déterminer s'il existe suffisamment de preuves pour rejeter l'hypothèse nulle, c'est-à-dire l'hypothèse qui suppose qu'il n'y a pas de relation entre deux variables. C'est important dans de nombreux domaines où il est essentiel de prendre des décisions éclairées en se basant sur des données, comme la recherche médicale, les sciences sociales et les affaires.
Lorsqu'on teste des hypothèses, on peut utiliser les coefficients z afin de déterminer la probabilité qu'un résultat se produise en particulier. Par exemple, vous pouvez tester si le poids moyen d'un groupe de personnes diffère du poids moyen de l'ensemble de la population. Vous pouvez utiliser le score z pour déterminer si la différence est statistiquement significative.
Le domaine médical représente un exemple pratique d'utilisation du score z pour tester des hypothèses. Par exemple, vous voulez tester si un nouveau médicament est efficace pour traiter les symptômes d'une certaine maladie. Vous pouvez utiliser le score z pour déterminer s'il y a une différence statistiquement significative entre les symptômes du groupe qui prend le médicament et les symptômes du groupe témoin.
Un autre exemple pratique d'utilisation du score z pour tester des hypothèses concerne le domaine de la finance. Par exemple, vous voulez tester si un stock particulier a un rendement plus élevé que le stock moyen sur le marché. Vous pouvez utiliser le score z pour déterminer si la différence entre les rendements est statistiquement significative.
Mise à l'échelle des caractéristiques
La mise à l'échelle des caractéristiques est une technique qu'on utilise dans l'apprentissage automatique et dans d'autres applications d'analyse de données pour s'assurer que toutes les caractéristiques d'une série de données sont à la même échelle. C'est important car certains algorithmes d'apprentissage automatique sont sensibles à l'échelle des données et ils peuvent engendrer des résultats inexacts si l'échelle ne correspond pas.
La normalisation du score z est une méthode courante pour mettre des caractéristiques à l'échelle. Cette méthode implique que chaque caractéristique soit convertie, afin que la valeur de sa moyenne soit égale à 0 et que son écart-type soit égal à 1. La formule pour calculer le score z d'une caractéristique est la suivante :
Z = (X - moyenne)/écart-type
où X correspond à la valeur de la caractéristique, moyenne correspond à la moyenne de la caractéristique et écart-type correspond à l'écart-type de la caractéristique.
Le domaine de la vision par ordinateur est un exemple pratique de l'utilisation du score z pour mettre des caractéristiques à l'échelle. Lorsque vous travaillez avec les données d'une image, il est généralement nécessaire de mettre les valeurs des pixels à l'échelle afin qu'elles se situent dans la plage de 0 à 1. Cela se fait en normalisant le score z, puisque la valeur de chaque pixel peut être transformée de sorte que sa valeur moyenne soit égale à 0 et son écart-type soit égal à 1.
Le traitement du langage naturel est un autre exemple pratique d'utilisation du score z pour la mise à l'échelle des caractéristiques. Lorsque vous travaillez avec des données textuelles, il est courant de mettre à l'échelle la fréquence des termes et la fréquence inverse des documents (TF-IDF) afin qu'elles se situent dans la plage de 0 à 1. On peut également le faire grâce à la normalisation du score z.
Modélisation prévisionnelle
La modélisation prévisionnelle est une technique qu'on utilise dans l'apprentissage automatique et dans d'autres applications d'analyse de données pour faire des prévisions basées sur des données historiques. Il s'agit de former un modèle à partir d'une série de données et d'utiliser ce modèle pour faire des prévisions sur de nouvelles données jamais observées.
La sélection des caractéristiques est un aspect important de la modélisation prévisionnelle, car elle consiste à sélectionner les caractéristiques les plus pertinentes de la série de données qu'il faut utiliser dans le modèle. Souvent, on préfère les caractéristiques qui sont fortement corrélées à la variable cible parce qu'elles sont plus susceptibles de la prévoir.
On peut utiliser le score z pour identifier les caractéristiques qui sont fortement corrélées à la variable cible, car les caractéristiques ayant un score z élevé sont plus susceptibles de prévoir la variable cible. La formule pour calculer le score z d'une caractéristique est la suivante :
Z = (X - moyenne)/écart-type
où X correspond à la valeur de la caractéristique, moyenne correspond à la moyenne de la caractéristique et écart-type correspond à l'écart-type de la caractéristique.
On retrouve dans le domaine de la finance un exemple pratique d'utilisation du score z en modélisation de pronostics. Lorsqu'on fait des prévisions sur le cours d'une action, on peut utiliser le score z des performances passées de l'action afin de déterminer les rendements potentiels dans le futur. Un score z élevé indique que le rendement passé d'une action est bien supérieur à la moyenne et que des rendements plus élevés peuvent être prévus pour le futur.
Le domaine des soins médicaux offre un autre exemple pratique de l'utilisation du score z en modélisation prévisionnelle. Lorsqu'on réalise des prévisions à propos des résultats médicaux de patients, on peut utiliser le score z afin de déterminer les possibles résultats futurs d'un patient. Un score z élevé révèle que les résultats médicaux d'un patient sont nettement plus mauvais que la moyenne et cela peut indiquer de mauvais résultats pour l'avenir.
Utilisation de la table des scores z
Une table z, qu'on appelle également table normale centrée réduite ou table normale standard, est une table qui contient des valeurs standardisées dont on se sert pour calculer la probabilité qu'une statistique donnée tombe en dessous, au-dessus ou entre la distribution normale centrée réduite.
| z | 0 | 0,01 | 0,02 | 0,03 | 0,04 | 0,05 | 0,06 | 0,07 | 0,08 | 0,09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0,00399 | 0,00798 | 0,01197 | 0,01595 | 0,01994 | 0,02392 | 0,0279 | 0,03188 | 0,03586 |
| 0,1 | 0,03983 | 0,0438 | 0,04776 | 0,05172 | 0,05567 | 0,05962 | 0,06356 | 0,06749 | 0,07142 | 0,07535 |
| 0,2 | 0,07926 | 0,08317 | 0,08706 | 0,09095 | 0,09483 | 0,09871 | 0,10257 | 0,10642 | 0,11026 | 0,11409 |
| 0,3 | 0,11791 | 0,12172 | 0,12552 | 0,1293 | 0,13307 | 0,13683 | 0,14058 | 0,14431 | 0,14803 | 0,15173 |
| 0,4 | 0,15542 | 0,1591 | 0,16276 | 0,1664 | 0,17003 | 0,17364 | 0,17724 | 0,18082 | 0,18439 | 0,18793 |
| 0,5 | 0,19146 | 0,19497 | 0,19847 | 0,20194 | 0,2054 | 0,20884 | 0,21226 | 0,21566 | 0,21904 | 0,2224 |
| 0,6 | 0,22575 | 0,22907 | 0,23237 | 0,23565 | 0,23891 | 0,24215 | 0,24537 | 0,24857 | 0,25175 | 0,2549 |
| 0,7 | 0,25804 | 0,26115 | 0,26424 | 0,2673 | 0,27035 | 0,27337 | 0,27637 | 0,27935 | 0,2823 | 0,28524 |
| 0,8 | 0,28814 | 0,29103 | 0,29389 | 0,29673 | 0,29955 | 0,30234 | 0,30511 | 0,30785 | 0,31057 | 0,31327 |
| 0,9 | 0,31594 | 0,31859 | 0,32121 | 0,32381 | 0,32639 | 0,32894 | 0,33147 | 0,33398 | 0,33646 | 0,33891 |
| 1 | 0,34134 | 0,34375 | 0,34614 | 0,34849 | 0,35083 | 0,35314 | 0,35543 | 0,35769 | 0,35993 | 0,36214 |
| 1,1 | 0,36433 | 0,3665 | 0,36864 | 0,37076 | 0,37286 | 0,37493 | 0,37698 | 0,379 | 0,381 | 0,38298 |
| 1,2 | 0,38493 | 0,38686 | 0,38877 | 0,39065 | 0,39251 | 0,39435 | 0,39617 | 0,39796 | 0,39973 | 0,40147 |
| 1,3 | 0,4032 | 0,4049 | 0,40658 | 0,40824 | 0,40988 | 0,41149 | 0,41308 | 0,41466 | 0,41621 | 0,41774 |
| 1,4 | 0,41924 | 0,42073 | 0,4222 | 0,42364 | 0,42507 | 0,42647 | 0,42785 | 0,42922 | 0,43056 | 0,43189 |
| 1,5 | 0,43319 | 0,43448 | 0,43574 | 0,43699 | 0,43822 | 0,43943 | 0,44062 | 0,44179 | 0,44295 | 0,44408 |
| 1,6 | 0,4452 | 0,4463 | 0,44738 | 0,44845 | 0,4495 | 0,45053 | 0,45154 | 0,45254 | 0,45352 | 0,45449 |
| 1,7 | 0,45543 | 0,45637 | 0,45728 | 0,45818 | 0,45907 | 0,45994 | 0,4608 | 0,46164 | 0,46246 | 0,46327 |
| 1,8 | 0,46407 | 0,46485 | 0,46562 | 0,46638 | 0,46712 | 0,46784 | 0,46856 | 0,46926 | 0,46995 | 0,47062 |
| 1,9 | 0,47128 | 0,47193 | 0,47257 | 0,4732 | 0,47381 | 0,47441 | 0,475 | 0,47558 | 0,47615 | 0,4767 |
| 2 | 0,47725 | 0,477778 | 0,47831 | 0,47882 | 0,47932 | 0,47982 | 0,4803 | 0,48077 | 0,48124 | 0,48169 |
| 2,1 | 0,48214 | 0,48257 | 0,483 | 0,48341 | 0,48382 | 0,48422 | 0,48461 | 0,485 | 0,48537 | 0,48574 |
| 2,2 | 0,4861 | 0,48645 | 0,48679 | 0,48713 | 0,48745 | 0,48778 | 0,48809 | 0,4884 | 0,4887 | 0,48899 |
| 2,3 | 0,48928 | 0,48956 | 0,48983 | 0,4901 | 0,49036 | 0,49061 | 0,49086 | 0,49111 | 0,49134 | 0,49158 |
| 2,4 | 0,4918 | 0,49202 | 0,49224 | 0,49245 | 0,49266 | 0,49286 | 0,49305 | 0,49324 | 0,49343 | 0,49361 |
| 2,5 | 0,49379 | 0,49396 | 0,49413 | 0,4943 | 0,49446 | 0,49461 | 0,49477 | 0,49492 | 0,49506 | 0,4952 |
| 2,6 | 0,49534 | 0,49547 | 0,4956 | 0,49573 | 0,49585 | 0,49598 | 0,49609 | 0,49621 | 0,49632 | 0,49643 |
| 2,7 | 0,49653 | 0,49664 | 0,49674 | 0,49683 | 0,49693 | 0,49702 | 0,49711 | 0,4972 | 0,49728 | 0,49736 |
| 2,8 | 0,49744 | 0,49752 | 0,4976 | 0,49767 | 0,49774 | 0,49781 | 0,49788 | 0,49795 | 0,49801 | 0,49807 |
| 2,9 | 0,49813 | 0,49819 | 0,49825 | 0,49831 | 0,49836 | 0,49841 | 0,49846 | 0,49851 | 0,49856 | 0,49861 |
| 3 | 0,49865 | 0,49869 | 0,49874 | 0,49878 | 0,49882 | 0,49886 | 0,49889 | 0,49893 | 0,49896 | 0,499 |
| 3,1 | 0,49903 | 0,49906 | 0,4991 | 0,49913 | 0,49916 | 0,49918 | 0,49921 | 0,49924 | 0,49926 | 0,49929 |
| 3,2 | 0,49931 | 0,49934 | 0,49936 | 0,49938 | 0,4994 | 0,49942 | 0,49944 | 0,49946 | 0,49948 | 0,4995 |
| 3,3 | 0,49952 | 0,49953 | 0,49955 | 0,49957 | 0,49958 | 0,4996 | 0,49961 | 0,49962 | 0,49964 | 0,49965 |
| 3,4 | 0,49966 | 0,49968 | 0,49969 | 0,4997 | 0,49971 | 0,49972 | 0,49973 | 0,49974 | 0,49975 | 0,49976 |
| 3,5 | 0,49977 | 0,49978 | 0,49978 | 0,49979 | 0,4998 | 0,49981 | 0,49981 | 0,49982 | 0,49983 | 0,49983 |
| 3,6 | 0,49984 | 0,49985 | 0,49985 | 0,49986 | 0,49986 | 0,49987 | 0,49987 | 0,49988 | 0,49988 | 0,49989 |
| 3,7 | 0,49989 | 0,4999 | 0,4999 | 0,49991 | 0,49991 | 0,49992 | 0,49992 | 0,49992 | 0,49992 | |
| 3,8 | 0,49993 | 0,49993 | 0,49993 | 0,49994 | 0,49994 | 0,49994 | 0,49994 | 0,49995 | 0,49995 | 0,49995 |
| 3,9 | 0,49995 | 0,49995 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49997 | 0,49997 |
| 4 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49998 | 0,49998 | 0,49998 | 0,49998 |
Pour utiliser la table z, vous devez trouver la ligne qui correspond au score z que vous avez calculé, puis trouver la colonne correspondante qui vous donne l'aire (probabilité) sous la courbe représentative de la loi normale centrée réduite. La valeur obtenue est la probabilité approximative qu'une variable aléatoire d'une distribution normale centrée réduite soit inférieure ou égale au score z de votre calcul.
Par exemple, si votre score z est de 1,96, vous devez chercher dans la table z la ligne qui correspond à 1,9 et la colonne qui correspond à 0,06. La valeur obtenue devrait vous donner l'aire sous la courbe représentative de la loi normale centrée réduite à droite de 1,96. Cette valeur est égale à 0,975 environ, ce qui signifie qu'environ 97,5 % des données d'une distribution normale centrée réduite sont inférieures ou égales à 1,96.
Il est important de noter que la table z marche uniquement dans le cas d'une distribution normale centrée réduite ayant une moyenne de 0 et un écart-type de 1. Si vos données n'observent pas cette distribution, vous devrez d'abord les normaliser en transformant les données en scores z.
Trouver la probabilité à partir du score z
Lorsque nous convertissons en score z une variable distribuée normalement, nous pouvons utiliser la table des scores z et trouver la proportion d'aire sous la courbe normale. L'aire totale sous la courbe normale centrée réduite est égale à 1. Par conséquent, pour une courbe normale, la proportion d'aire grisée est égale à la probabilité de ce score z.
Exemple 1
Le poids des joueurs de boxe est distribué normalement avec une moyenne de 75 kg et un écart-type de 3 kg. Quelle est la probabilité qu'un joueur choisi au hasard pèse :
- a) plus de 78 kg ?
- b) moins de 69 kg ?
- c) plus de 72 kg ?
- d) moins de 79,5 kg ?
- e) entre 72 kg et 76,5 kg ?
- f) entre 72 kg et 73,5 kg ?
a) Quelle est la probabilité qu'un joueur choisi au hasard pèse plus de 78 kg ?
- X > 78
- μ = 75
- σ = 3
$$P(X>78)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{78-75}{3}\right)=P(Z>1)$$
Tout d'abord, nous allons tracer ceci suivant une courbe z.
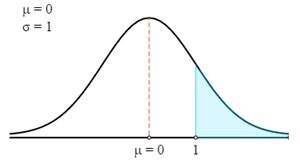
À présent, nous allons utiliser la table z pour trouver la probabilité correspondant au score z calculé.
N'oubliez pas que le score z donne toujours la probabilité entre le score z et la moyenne. Pour obtenir la probabilité de la zone du graphique en surbrillance, nous devons soustraire cette probabilité de 0,5. (La probabilité totale sous la courbe est égale à 1 et la moyenne de la distribution normale centrée réduite la divise en 2 parties égales. Par conséquent, la probabilité entre un point de la moyenne et la limite d'un côté ou de l'autre est égale à 0,5).
- P (X > 78) = P (Z > 1)
- P (X > 78) = 0,5 - P (0 < Z < 1)
- P (X > 78) = 0,5 - 0,3413
- P (X > 78) = 0,1587
Par conséquent, la probabilité que le poids d'un joueur sélectionné au hasard soit supérieur à 78 kg est égale à 0,1587.
a) Quelle est la probabilité qu'un joueur choisi au hasard pèse moins de 69 kg ?
- X < 69
- μ = 75
- σ = 3
$$P(X<69)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{69-75}{3}\right)=P(Z<-2)$$
Tout d'abord, nous allons tracer ceci suivant une courbe z.
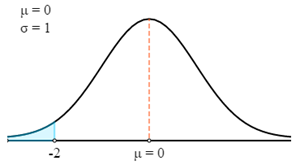
À présent, nous allons utiliser la table z pour trouver la probabilité correspondant au score z calculé.
N'oubliez pas que le score z donne toujours la probabilité entre le score z et la moyenne. Pour obtenir la probabilité de la zone du graphique en surbrillance, nous devons soustraire cette probabilité de 0,5.
- P (X < 69) = P (Z < 69)
- P (X < 69) = 0,5 - P (0 > Z > -2)
- P (X < 69) = 0,5 - 0,4772
- P (X < 69) = 0,0228
Par conséquent, la probabilité que le poids d'un joueur sélectionné au hasard soit inférieur à 69 kg est égale à 0,1587.
c) Quelle est la probabilité que le poids d'un joueur choisi au hasard se situe entre 72 kg et 76,5 kg ?
- 72 < X < 76,5
- μ = 75
- σ = 3
$$P(72 \lt X \lt 76,5)=P\left(\frac{X-μ}{σ} \lt Z \lt \frac{X-μ}{σ}\right)=P\left(\frac{72-75}{3} \lt Z \lt \frac{76,5-75}{3}\right)=P(-1 \lt Z \lt 0,5)$$
Tout d'abord, nous allons tracer ceci suivant une courbe z.
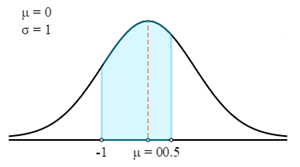
À présent, nous allons utiliser la table z pour trouver la probabilité correspondant au score z calculé.
N'oubliez pas que le score z donne toujours la probabilité entre le score z et la moyenne. Pour obtenir la probabilité de la zone en surbrillance dans le graphique, vous pouvez additionner les probabilités de 2 scores z ensemble.
- P (72 < X < 76,5) = P (-1 < Z < 0,5)
- P (72 < X < 76,5) = 0,3413 + 0,1915
- P (72 < X < 76,5) = 0,5328
Par conséquent, la probabilité que le poids d'un joueur sélectionné au hasard soit compris entre 72 kg et 76,5 kg est égale à 0,5328.
Dans ce cas, vous devez utiliser la calculatrice de probabilité entre deux scores z pour trouver la réponse rapidement.
Trouver les valeurs correspondant à une probabilité déterminée
Si nous savons que la distribution est normale, nous pouvons trouver les valeurs correspondant à des probabilités déterminées en se basant sur le score z.
Exemple 2
Les notes des candidats à un concours sont à peu près réparties normalement, avec une moyenne de 55 et un écart-type de 10. Si 30 % des candidats réussissent l'examen, trouvez la note minimale de réussite au concours.
Réponse
Dans ce cas, nous devons d'abord trouver le score z correspondant pour la probabilité ou le pourcentage donné.
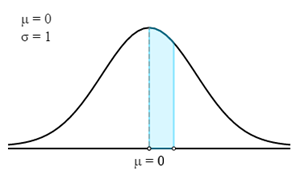
Pour trouver le score z, nous devons en fait trouver la probabilité de la zone en surbrillance.
On l'obtient en déduisant 0,30 de 0,50. Par conséquent, la probabilité de la zone en surbrillance est de 0,20.
Maintenant, dans la table z, nous devons trouver la probabilité la plus proche de 0,20. Le score z correspondant est de 0,524.
Ensuite, nous devons trouver la valeur de X en utilisant la formule du score z.
- Z = (X - μ)/σ
- 0,524 = (X - 55)/10
- X = (0,524 × 10) + 55
- X = 60,24
Par conséquent, la note de réussite minimale pour l'examen est de 60,24.