結果が見つかりません
現在、その用語では何も見つかりません。他の検索を試してください。
Z-スコア計算機
Zスコア計算機は、正規分布のZスコアを取得するのに役立ちます, Z スコアと確率の間の変換, 2つのZスコア間の確率を取得します。
| 結果 | ||
|---|---|---|
| Zスコア | 1 | |
| の確率 x<5 | 0.84134 | |
| の確率 x>5 | 0.15866 | |
| の確率 3<x<5 | 0.34134 | |
| 結果 | ||
|---|---|---|
| Zスコア | 2 | |
| P(x<Z) | 0.97725 | |
| P(x>Z) | 0.02275 | |
| P(0<x<Z) | 0.47725 | |
| P(-Z<x<Z) | 0.9545 | |
| P(x<-Z or x>Z) | 0.0455 | |
| 結果 | ||
|---|---|---|
| P(-1<x<0) | 0.34134 | |
| P(x<-1 or x>0) | 0.65866 | |
| P(x<-1) | 0.15866 | |
| P(x>0) | 0.5 | |
計算にエラーがありました。
目次
- Zスコアとは何ですか?
- Z-スコア式
- 得られたZスコアの結果の解釈
- Z スコアと標準偏差
- Zスコアと正規分布
- データポイントの比較
- データの正規化
- 仮説検定
- 機能のスケーリング
- 予測モデリング
- Z スコア テーブルの使用
- Zスコアから確率を求める
- 指定された確率に対応する値を見つける

Z スコア計算機は、あらゆるタイプの Z スコア関連の計算に使用できます。 最初の計算機に生のスコア (X) 、 母平均 (μ) 、および標準偏差 (σ) を入力して、その行スコアにステップおよび関連する確率を含む Z スコアを見つけることができます。
Z スコアと確率コンバーターを使用すると、Z テーブルを参照せずに Z スコアと確率を変換できます。 結果には、その単一の z スコアで可能なすべての確率計算が含まれます。 最後の計算機を使用して、2 つの Z スコア間の確率を見つけます。
Zスコアとは何ですか?
Z スコアは、データ セットの平均からのデータ ポイントの標準偏差の数を表す統計的尺度です。 Z スコアは、単一のデータ ポイントをデータ セット全体と比較するために使用され、データを標準化して比較と分析を容易にするのに役立ちます。
Z スコアにより、単一のデータ ポイントがデータ セット全体と比較してどの程度”典型的”または逆に”非典型的”であるかを判断できます。
- 外れ値の検出: Zスコアは、他のデータとは大幅に異なるデータポイントを特定するのに役立ちます。これは、財務や医学研究など、外れ値が重要なパターンや異常を示す可能性がある分野で役立ちます。
- 異なるセットのデータを比較する: Zスコアを使用すると、単位や範囲が異なる場合でも、異なるセットのデータを比較できます。これは、モデルを構築するためにさまざまなソースからのデータを比較する必要がある機械学習などの領域で役立ちます。
- データの正規化: データをZスコアに変換することで、データを標準化し、比較と分析を容易にすることができます。これは、データの視覚化など、データをわかりやすい方法で提示する必要がある分野で役立ちます。
Z-スコア式
母集団のZスコア
Z =生のスコア-母集団平均/母標準偏差
Z = (X - μ) / σ
サンプルのZスコア
Z =生のスコア-サンプル平均/サンプル標準偏差
Z = (X - x̄) / s
得られたZスコアの結果の解釈
正の Z スコア: 正の Z スコアは、データ ポイントがデータセットの平均値を上回っていることを意味します。つまり、観測されたデータポイントはデータセットの典型的な値よりも高くなっています。
負の Z スコア: 負の Z スコアは、データ ポイントがデータセットの平均値を下回っていることを意味します。つまり、観測されたデータポイントはデータセットの典型的な値よりも低くなっています。
Z スコア: Z スコアは、データ ポイントがデータセットの平均からどれだけ離れているかを示します。Zスコアが大きいほど、観測データポイントは平均値から離れています。
Z スコアと標準偏差
Z スコアの計算には標準偏差が使用されるため、Z スコアと標準偏差は関連しています。実際、標準偏差はZスコア式の重要な要素です。
標準偏差は、データセットの広がりの尺度です。これは、各データポイントがデータセットの平均値からどれだけ離れているかを示します。標準偏差が大きいほど、データの分散が大きくなります。
一方、Zスコアは、標準偏差に対するデータセットの平均から1つのデータポイントがどれだけ離れているかを示します。標準偏差を使用してZスコアを計算することにより、1つのデータポイントをデータセット全体と比較して、それがどれほど異常または典型的であるかを確認できます。
Zスコアと正規分布
正規分布は、多くの現実世界の現象でよく見られる分布の一種です。
これは、一連のデータの平均付近のデータの分布を表す釣鐘型の曲線です。
正規分布は、数学者カール・フリードリッヒ・ガウスにちなんで、ガウス分布としても知られています。
Zスコアは、標準偏差に対するデータセットの平均から1つのデータポイントがどれだけ離れているかを測定する方法です。各データポイントをZスコアに変換することで、個々のデータポイントをデータセット全体と比較して、それがどれほど異常または典型的であるかを確認できます。
Zスコアと正規分布の関係は、Zスコアを使用してデータを標準化し、正規分布に適合させることができることです。つまり、各データ ポイントを Z スコアに変換することで、任意のデータ セットを正規分布に変換できます。これは、多くの統計手法ではデータが正規分布であることを前提としているため、データを正規分布に変換すると、これらの手法をより正確に使用できるようになるため、便利です。
データポイントの比較
Z スコアは、標準偏差に対するデータ セットの平均から 1 つのデータ ポイントがどれだけ離れているかを理解するのに役立ちます。
Z スコアを使用してデータ ポイントを比較する例は、金融に適用されます。 たとえば、2 つの異なる株式ポートフォリオに投資しており、そのパフォーマンスを比較したいとします。 ポートフォリオ A の平均リターンは標準偏差 2% で 10% であり、ポートフォリオ B の平均リターンは標準偏差 3% で 8% です。 リターンを Z スコアに変換することで、各ポートフォリオのリターンを比較し、どちらのパフォーマンスが優れているかを判断できます。 Z スコアを使用してデータ ポイントを比較するもう 1 つの実用的な例は、スポーツです。 たとえば、2 人のバスケットボール プレーヤー、プレーヤー A とプレーヤー B のパフォーマンスを比較するとします。プレーヤー A は 5 ポイントの標準偏差で 1 ゲームあたり平均 20 ポイントを獲得し、プレーヤー B は 1 ゲームあたり平均 18 ポイントを獲得します。 3ポイントの標準偏差。 スコアを Z スコアに変換することで、各プレーヤーのパフォーマンスを比較し、どちらのプレーヤーのパフォーマンスが優れているかを判断できます。
データの正規化
データの正規化は、データを簡単に比較および分析できるように、データを標準スケールに変換するプロセスです。データはさまざまな形状とスケールを持つことができ、データを正規化すると同じスケールになり、比較と分析が容易になるため、これは重要です。
各データ ポイントを Z スコアに変換することで、データを標準化して同じスケールに配置できます。これは、Z スコアが常に標準スケールであり、平均が 0、標準偏差が 1 であるためです。
Zスコアを使用してデータを正規化する1つの実用的な例は、心理学の分野に関連しています。たとえば、テスト A とテスト B の 2 つの IQ テストの結果を比較するとします。テスト A の平均スコアは 100 で標準偏差は 15 で、テスト B の平均スコアは 110 で標準偏差は 10 です。スコアをZスコアに変換することで、スコアを標準化して単一のスケールに縮小できるため、比較と分析が容易になります。
Zスコアを使用してデータを正規化する別の実用的な例は、教育です。たとえば、学生Aと学生Bの2人の学生の成績を比較するとします。学生Aの平均成績は80で標準偏差は5で、学生Bの平均成績は90で標準偏差は3です。成績をZ係数に変換することで、成績を標準化し、すべて同じスケールにすることができ、比較と分析が容易になります。
仮説検定
仮説検定は、帰無仮説を棄却するのに十分な証拠があるかどうか、または2つの変数間に関係がないという標準的な仮定があるかどうかを判断するために使用される統計的手法です。医学研究、社会科学、ビジネスなど、データに基づいて情報に基づいた意思決定を行うことが重要となる多くの分野で重要です。
仮説を検定する場合、Z係数を使用して、特定の結果が発生する確率を判断できます。たとえば、ある集団の平均体重が母集団全体の平均体重と異なるかどうかを検定できます。Zスコアを使用して、差が統計的に有意かどうかを判断できます。
Zスコアを使用して仮説をテストする実用的な例の1つは、医療分野です。たとえば、新薬が特定の病気の症状を軽減するのに効果的かどうかをテストしたいとします。Zスコアを使用して、薬を服用しているグループと対照グループの症状の差が統計的に有意かどうかを判断できます。
仮説をテストするためにZスコアを使用する別の実用的な例は、金融の分野です。たとえば、特定の株式のリターンが市場の平均株式よりも高いかどうかを検定するとします。Zスコアを使用して、返品の差が統計的に有意かどうかを判断できます。
機能のスケーリング
特徴スケーリングは、機械学習やその他のデータ分析アプリケーションで、データセット内のすべての特徴が同じ縮尺になるようにする手法です。一部の機械学習アルゴリズムはデータのスケールに敏感であり、スケールが一致しない場合に不正確な結果が生成される可能性があるため、これは重要です。
特性をスケーリングする一般的な方法の 1 つは、標準化とも呼ばれる Z スコアの正規化です。 このプロセスでは、平均値が 0、標準偏差が 1 になるように、各形質が変換されます。形質の Z スコアを計算する式は次のとおりです:
Z = (X -平均) /標準偏差
ここで、X は地物の値、平均は地物の平均、標準偏差は地物の標準偏差です。
Z スコアを使用してフィーチャをスケーリングする実際的な例は、コンピューター ビジョンの分野にあります。 画像データを操作する場合、通常、ピクセル値が 0 から 1 の範囲になるようにスケーリングする必要があります。これは、Z スコアを正規化することで実現できます。これは、各ピクセル値がその平均になるように変換できるためです。値は 0 で、その標準偏差は 1 です。
特徴のスケーリングに Z スコアを使用するもう 1 つの実用的な例は、自然言語処理です。 テキスト データを扱う場合、用語の頻度と逆ドキュメント頻度 (TF-IDF) の値をスケーリングして、それらが 0 から 1 の範囲になるようにするのが一般的です。これは、Z スコアの正規化を使用して達成することもできます。
予測モデリング
予測モデリングは、機械学習やその他のデータ分析アプリケーションで履歴データに基づいて予測を行うために使用される手法です。これには、データセットでモデルをトレーニングし、そのモデルを使用して新しい目に見えないデータで予測を行うことが含まれます。
予測モデリングの重要な側面の 1 つは特徴選択であり、モデルで使用するためにデータ セットから最も関連性の高い特徴を選択します。多くの場合、ターゲット変数と高い相関性を持つ特性は、ターゲット変数を予測する可能性が高いため、好まれます。
Z スコアが高い特性はターゲット変数を予測する可能性が高いため、Z スコアを使用して、ターゲット変数と高い相関性を持つ特性を特定できます。特性のZスコアを計算する式は次のとおりです:
Z = (X -平均) /標準偏差
ここで、X は地物の値、平均は地物の平均、標準偏差は地物の標準偏差です。
予測モデリングで Z スコアを使用する実際の例は、金融の分野に属します。 株価を予測する場合、株式の過去のパフォーマンスの Z スコアを使用して、将来のリターンの可能性を判断できます。 高い Z スコアは、株式の過去のリターンが平均をはるかに上回っており、将来的にはより高いリターンが予測できることを示します。
予測モデリングで Z スコアを使用するもう 1 つの実用的な例は、ヘルスケア分野です。
患者の転帰を予測する場合、Z スコアを使用して、将来の転帰に対する患者の可能性を判断できます。 高い Z スコアは、患者の健康転帰が平均よりも著しく悪いことを示し、将来の転帰が悪いことを示している可能性があります。
Z スコア テーブルの使用
zテーブルは、標準正規表または単位正規表とも呼ばれ、特定の統計量が標準正規分布を下回る、上回る、または標準正規分布の間に入る確率を計算するために使用される標準化された値を含む表です。
| z | 0 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.00399 | 0.00798 | 0.01197 | 0.01595 | 0.01994 | 0.02392 | 0.0279 | 0.03188 | 0.03586 |
| 0.1 | 0.03983 | 0.0438 | 0.04776 | 0.05172 | 0.05567 | 0.05962 | 0.06356 | 0.06749 | 0.07142 | 0.07535 |
| 0.2 | 0.07926 | 0.08317 | 0.08706 | 0.09095 | 0.09483 | 0.09871 | 0.10257 | 0.10642 | 0.11026 | 0.11409 |
| 0.3 | 0.11791 | 0.12172 | 0.12552 | 0.1293 | 0.13307 | 0.13683 | 0.14058 | 0.14431 | 0.14803 | 0.15173 |
| 0.4 | 0.15542 | 0.1591 | 0.16276 | 0.1664 | 0.17003 | 0.17364 | 0.17724 | 0.18082 | 0.18439 | 0.18793 |
| 0.5 | 0.19146 | 0.19497 | 0.19847 | 0.20194 | 0.2054 | 0.20884 | 0.21226 | 0.21566 | 0.21904 | 0.2224 |
| 0.6 | 0.22575 | 0.22907 | 0.23237 | 0.23565 | 0.23891 | 0.24215 | 0.24537 | 0.24857 | 0.25175 | 0.2549 |
| 0.7 | 0.25804 | 0.26115 | 0.26424 | 0.2673 | 0.27035 | 0.27337 | 0.27637 | 0.27935 | 0.2823 | 0.28524 |
| 0.8 | 0.28814 | 0.29103 | 0.29389 | 0.29673 | 0.29955 | 0.30234 | 0.30511 | 0.30785 | 0.31057 | 0.31327 |
| 0.9 | 0.31594 | 0.31859 | 0.32121 | 0.32381 | 0.32639 | 0.32894 | 0.33147 | 0.33398 | 0.33646 | 0.33891 |
| 1 | 0.34134 | 0.34375 | 0.34614 | 0.34849 | 0.35083 | 0.35314 | 0.35543 | 0.35769 | 0.35993 | 0.36214 |
| 1.1 | 0.36433 | 0.3665 | 0.36864 | 0.37076 | 0.37286 | 0.37493 | 0.37698 | 0.379 | 0.381 | 0.38298 |
| 1.2 | 0.38493 | 0.38686 | 0.38877 | 0.39065 | 0.39251 | 0.39435 | 0.39617 | 0.39796 | 0.39973 | 0.40147 |
| 1.3 | 0.4032 | 0.4049 | 0.40658 | 0.40824 | 0.40988 | 0.41149 | 0.41308 | 0.41466 | 0.41621 | 0.41774 |
| 1.4 | 0.41924 | 0.42073 | 0.4222 | 0.42364 | 0.42507 | 0.42647 | 0.42785 | 0.42922 | 0.43056 | 0.43189 |
| 1.5 | 0.43319 | 0.43448 | 0.43574 | 0.43699 | 0.43822 | 0.43943 | 0.44062 | 0.44179 | 0.44295 | 0.44408 |
| 1.6 | 0.4452 | 0.4463 | 0.44738 | 0.44845 | 0.4495 | 0.45053 | 0.45154 | 0.45254 | 0.45352 | 0.45449 |
| 1.7 | 0.45543 | 0.45637 | 0.45728 | 0.45818 | 0.45907 | 0.45994 | 0.4608 | 0.46164 | 0.46246 | 0.46327 |
| 1.8 | 0.46407 | 0.46485 | 0.46562 | 0.46638 | 0.46712 | 0.46784 | 0.46856 | 0.46926 | 0.46995 | 0.47062 |
| 1.9 | 0.47128 | 0.47193 | 0.47257 | 0.4732 | 0.47381 | 0.47441 | 0.475 | 0.47558 | 0.47615 | 0.4767 |
| 2 | 0.47725 | 0.47778 | 0.47831 | 0.47882 | 0.47932 | 0.47982 | 0.4803 | 0.48077 | 0.48124 | 0.48169 |
| 2.1 | 0.48214 | 0.48257 | 0.483 | 0.48341 | 0.48382 | 0.48422 | 0.48461 | 0.485 | 0.48537 | 0.48574 |
| 2.2 | 0.4861 | 0.48645 | 0.48679 | 0.48713 | 0.48745 | 0.48778 | 0.48809 | 0.4884 | 0.4887 | 0.48899 |
| 2.3 | 0.48928 | 0.48956 | 0.48983 | 0.4901 | 0.49036 | 0.49061 | 0.49086 | 0.49111 | 0.49134 | 0.49158 |
| 2.4 | 0.4918 | 0.49202 | 0.49224 | 0.49245 | 0.49266 | 0.49286 | 0.49305 | 0.49324 | 0.49343 | 0.49361 |
| 2.5 | 0.49379 | 0.49396 | 0.49413 | 0.4943 | 0.49446 | 0.49461 | 0.49477 | 0.49492 | 0.49506 | 0.4952 |
| 2.6 | 0.49534 | 0.49547 | 0.4956 | 0.49573 | 0.49585 | 0.49598 | 0.49609 | 0.49621 | 0.49632 | 0.49643 |
| 2.7 | 0.49653 | 0.49664 | 0.49674 | 0.49683 | 0.49693 | 0.49702 | 0.49711 | 0.4972 | 0.49728 | 0.49736 |
| 2.8 | 0.49744 | 0.49752 | 0.4976 | 0.49767 | 0.49774 | 0.49781 | 0.49788 | 0.49795 | 0.49801 | 0.49807 |
| 2.9 | 0.49813 | 0.49819 | 0.49825 | 0.49831 | 0.49836 | 0.49841 | 0.49846 | 0.49851 | 0.49856 | 0.49861 |
| 3 | 0.49865 | 0.49869 | 0.49874 | 0.49878 | 0.49882 | 0.49886 | 0.49889 | 0.49893 | 0.49896 | 0.499 |
| 3.1 | 0.49903 | 0.49906 | 0.4991 | 0.49913 | 0.49916 | 0.49918 | 0.49921 | 0.49924 | 0.49926 | 0.49929 |
| 3.2 | 0.49931 | 0.49934 | 0.49936 | 0.49938 | 0.4994 | 0.49942 | 0.49944 | 0.49946 | 0.49948 | 0.4995 |
| 3.3 | 0.49952 | 0.49953 | 0.49955 | 0.49957 | 0.49958 | 0.4996 | 0.49961 | 0.49962 | 0.49964 | 0.49965 |
| 3.4 | 0.49966 | 0.49968 | 0.49969 | 0.4997 | 0.49971 | 0.49972 | 0.49973 | 0.49974 | 0.49975 | 0.49976 |
| 3.5 | 0.49977 | 0.49978 | 0.49978 | 0.49979 | 0.4998 | 0.49981 | 0.49981 | 0.49982 | 0.49983 | 0.49983 |
| 3.6 | 0.49984 | 0.49985 | 0.49985 | 0.49986 | 0.49986 | 0.49987 | 0.49987 | 0.49988 | 0.49988 | 0.49989 |
| 3.7 | 0.49989 | 0.4999 | 0.4999 | 0.4999 | 0.49991 | 0.49991 | 0.49992 | 0.49992 | 0.49992 | 0.49992 |
| 3.8 | 0.49993 | 0.49993 | 0.49993 | 0.49994 | 0.49994 | 0.49994 | 0.49994 | 0.49995 | 0.49995 | 0.49995 |
| 3.9 | 0.49995 | 0.49995 | 0.49996 | 0.49996 | 0.49996 | 0.49996 | 0.49996 | 0.49996 | 0.49997 | 0.49997 |
| 4 | 0.49997 | 0.49997 | 0.49997 | 0.49997 | 0.49997 | 0.49997 | 0.49998 | 0.49998 | 0.49998 | 0.49998 |
Z テーブルを使用するには、計算された Z スコアに対応する行を見つけてから、標準正規曲線の下の面積 (確率) を示す対応する列を見つける必要があります。結果の値は、標準正規分布の確率変数が計算された Z スコア以下になるおおよその確率です。
たとえば、Z スコアが 1.96 の場合、Z テーブルで 1.9 に対応する行と 0.06 に対応する列を検索します。 結果の値は、1.96 の右側の標準正規曲線の下の領域を示します。 この値は約 0.975 で、標準正規分布のデータの約 97.5% が 1.96 以下であることを意味します。
Z テーブルは、平均が 0、標準偏差が 1 の標準正規分布に対してのみ機能することに注意してください。データがこの分布に従わない場合は、まずデータを Z スコアに変換して標準化する必要があります。
Zスコアから確率を求める
正規分布変数をZスコアに変換する場合、Zスコアテーブルを使用して、正規曲線の下の面積の比率を見つけることができます。標準正規曲線の下の総面積は1に等しくなります。したがって、正規曲線でカバーされる面積の割合は、そのZスコアの確率に等しくなります。
例1
ボクシング選手の体重は、平均75 Kg、標準偏差3 Kgで正規分布しています。ランダムに選択されたプレーヤーの体重がそうである確率はどれくらいですか;
- a) 78キロ以上?
- b) 69kg未満?
- c) 72キロ以上?
- d) 79.5キロ未満?
- e) 72キロから76.5キロの間?
- f) 72キロから73.5キロの間?
a) ランダムに選ばれたプレイヤーの体重が78kgを超える確率はどれくらいですか?
- X > 78
- μ = 75
- σ = 3
$$P(X>78)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{78-75}{3}\right)=P(Z>1)$$
まず、これをZ曲線で描画します。
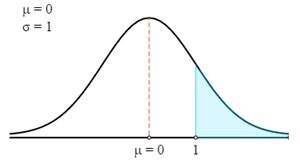
次に、Zテーブルを使用して、計算されたZスコアに関連する確率を見つけます。 Z スコアは、常に Z スコアと平均の間の確率を与えることに注意してください。 グラフで強調表示された領域の確率を取得するには、その確率を 0.5 から減らす必要があります。 (曲線の下の合計確率は 1 で、標準分布の平均は 2 つの部分に均等に分離されます。したがって、平均点から端の両側までの確率は 0.5 です。)
- P (X > 78) = P (Z > 1)
- P (X > 78) = 0.5 - P(0 < Z < 1)
- P (X > 78) = 0.5 - 0.3413
- P (X > 78) = 0.1587
したがって、ランダムに選択されたプレーヤーの体重が78 Kgを超える確率は0.1587です。 b) ランダムに選択されたプレーヤーの体重が69kg未満である確率はどれくらいですか?
- X < 69
- μ = 75
- σ = 3
$$P(X<69)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{69-75}{3}\right)=P(Z<-2)$$
まず、これをZ曲線で描画します。
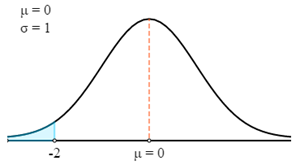
次に、Zテーブルを使用して、計算されたZスコアに関連する確率を見つけます。 Zスコアは常にZスコアと平均の間の確率を与えることに注意してください。グラフで強調表示された領域の確率を取得するには、その確率を0.5から減らす必要があります。
- P (X < 69) = P (Z < 69)
- P (X < 69) = 0.5 - P (0 > Z > -2)
- P (X < 69) = 0.5 - 0.4772
- P (X < 69) = 0.0228
したがって、ランダムに選択されたプレーヤーの体重が69 Kg未満である確率は0.0228です。 c) ランダムに選択されたプレーヤーの体重が72kgから76.5kgである確率はどれくらいですか?
- 72 < X < 76.5
- μ = 75
- σ = 3
$$P(72 \lt X \lt 76.5)=P\left(\frac{X-μ}{σ} \lt Z \lt \frac{X-μ}{σ}\right)=P\left(\frac{72-75}{3} \lt Z \lt \frac{76.5-75}{3}\right)=P(-1 \lt Z \lt 0.5)$$
まず、これをZ曲線で描画します。
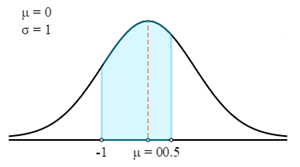
次に、Zテーブルを使用して、計算されたZスコアに関連する確率を見つけます。 Zスコアは常にZスコアと平均の間の確率を与えることに注意してください。グラフで強調表示された領域の確率を取得するには、2つのZスコアの確率を加算します。
- P (72 < X < 76.5) = P (-1 < Z < 0.5)
- P (72 < X < 76.5) = 0.3413 + 0.1915
- P (72 < X < 76.5) = 0.5328
したがって、ランダムに選択されたプレーヤーの体重が72 Kgから76.5 Kgの間であるという確率は0.5328です。 この場合、答えをすばやく見つけるには、2つのZスコア計算機を使用する必要があります。
指定された確率に対応する値を見つける
分布が正規であることがわかっている場合は、Zスコアに基づいて指定された確率に対応する値を見つけることができます。
例 2
競争試験の申請者の点数はほぼ正規分布しており、平均は55、標準偏差は10です。志願者の上位30%がテストに合格した場合は、最低合格点を見つけます。
解決
この場合、最初に、指定された確率またはパーセンテージに対応するZスコアを見つける必要があります。
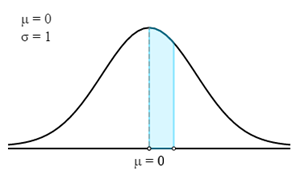
Zスコアを見つけるには、強調表示された領域で確率を見つける必要があります。
0.50から0.30を差し引いた値です。 したがって、強調表示された領域の確率は 0.20 です。
ここで、Z テーブルで、0.20 に最も近い確率を見つける必要があります。 対応する Z スコアは 0.524 です。 次に、Z スコア式を使用して X 値を見つける必要があります。
- Z = (X - μ)/σ
- 0.524 = (X - 55)/10
- X = (0.524 × 10) + 55
- X = 60.24
したがって、試験の合格最低点は 60.24 です。