결과를 찾을 수 없습니다
현재 그 용어로는 아무것도 찾을 수 없습니다, 다른 것을 검색해보세요.
확률 계산기
확률 계산기는 두 사건의 확률과 정규 분포 확률을 찾을 수 있습니다. 확률의 법칙과 계산에 대해 더 알아보세요.
| 결과 | ||
|---|---|---|
| A가 발생하지 않을 확률: P(A') | 0.5 | |
| B가 발생하지 않을 확률: P(B') | 0.6 | |
| A와 B 모두 발생할 확률: P(A∩B) | 0.2 | |
| A나 B 또는 둘 다 발생할 확률: P(A∪B) | 0.7 | |
| A나 B가 발생하지만 둘 다는 아닐 확률: P(AΔB) | 0.5 | |
| A도 B도 발생하지 않을 확률: P((A∪B)') | 0.3 | |
| A는 발생하지만 B는 발생하지 않을 확률: | 0.3 | |
| B는 발생하지만 A는 발생하지 않을 확률: | 0.2 | |
Probability
A의 확률: P(A) = 0.5
B의 확률: P(B) = 0.4
A가 발생하지 않을 확률: P(A') = 1 - P(A) = 0.5
B가 발생하지 않을 확률: P(B') = 1 - P(B) = 0.6
A와 B 모두 발생할 확률: P(A∩B) = P(A) × P(B) = 0.2
A나 B 또는 둘 다 발생할 확률: P(A∪B) = P(A) + P(B) - P(A∩B) = 0.7
A나 B가 발생하지만 둘 다는 아닐 확률: P(AΔB) = P(A) + P(B) - 2P(A∩B) = 0.5
A도 B도 발생하지 않을 확률: P((A∪B)') = 1 - P(A∪B) = 0.3
A는 발생하지만 B는 발생하지 않을 확률: P(A) × (1 - P(B)) = 0.3
B는 발생하지만 A는 발생하지 않을 확률: (1 - P(A)) × P(B) = 0.2
Probability
A가 5회 발생할 확률 = 0.65 = 0.07776
A가 발생하지 않을 확률 = (1-0.6)5 = 0.01024
A가 발생할 확률 = 1-(1-0.6)5 = 0.98976
B가 3회 발생할 확률 = 0.33 = 0.027
B가 발생하지 않을 확률 = (1-0.3)3 = 0.343
B가 발생할 확률 = 1-(1-0.3)3 = 0.657
A가 5회 그리고 B가 3회 발생할 확률 = 0.65 × 0.33 = 0.00209952
A도 B도 발생하지 않을 확률 = (1-0.6)5 × (1-0.3)3 = 0.00351232
A와 B 모두 발생할 확률 = (1-(1-0.6)5) × (1-(1-0.3)3) = 0.65027232
A가 5회 발생하지만 B는 발생하지 않을 확률 = 0.65 × (1-0.3)3 = 0.02667168
B가 3회 발생하지만 A는 발생하지 않을 확률 = (1-0.6)5 × 0.33 = 2.7648e-4
A가 발생하지만 B는 발생하지 않을 확률 = (1-(1-0.6)5) × (1-0.3)3 = 0.33948768
B가 발생하지만 A는 발생하지 않을 확률 = (1-0.6)5 × (1-(1-0.3)3) = 0.00672768
Probability
-1과 1 사이의 확률은 0.68268입니다
-1과 1의 외부 확률은 0.31732입니다
-1 이하(≤-1)의 확률은 0.15866입니다
1 이상(≥1)의 확률은 0.15866입니다
| 신뢰 구간 표 | ||
|---|---|---|
| 신뢰도 | 범위 | N |
| 0.6828 | -1.00000 – 1.00000 | 1 |
| 0.8 | -1.28155 – 1.28155 | 1.281551565545 |
| 0.9 | -1.64485 – 1.64485 | 1.644853626951 |
| 0.95 | -1.95996 – 1.95996 | 1.959963984540 |
| 0.98 | -2.32635 – 2.32635 | 2.326347874041 |
| 0.99 | -2.57583 – 2.57583 | 2.575829303549 |
| 0.995 | -2.80703 – 2.80703 | 2.807033768344 |
| 0.998 | -3.09023 – 3.09023 | 3.090232306168 |
| 0.999 | -3.29053 – 3.29053 | 3.290526731492 |
| 0.9999 | -3.89059 – 3.89059 | 3.890591886413 |
| 0.99999 | -4.41717 – 4.41717 | 4.417173413469 |
계산에 오류가 있었습니다.
목차
- 두 사건의 확률 계산기
- 두 사건에 대한 확률 해결기
- 독립적인 사건들의 연속 확률
- 정규 분포의 확률
- 확률 소개
- 사건 연산 규칙
- 예제
- 사건의 보완
- 사건의 교집합
- 독립 사건
- 사건의 합집합
- 정규 분포
- 정규 분포의 확률
- 예제

두 사건의 확률 계산기
두 독립적인 사건의 확률을 알고 있다면, 두 사건이 함께 발생할 확률을 결정하기 위해 두 사건의 확률 계산기를 사용할 수 있습니다. 계산기에서 두 독립 사건의 확률을 a와 b의 확률로 입력해야 합니다. 그러면 계산기는 두 독립 사건의 합집합, 교집합 및 관련 확률과 함께 벤 다이어그램을 보여줍니다.
두 사건에 대한 확률 해결기
두 독립 사건의 다양한 사건 확률을 계산할 수 있습니다. 이것은 두 사건의 확률 중 하나 또는 둘 다 없을 때 중요합니다. 결과는 계산 단계와 함께 답을 보여줄 것입니다.
독립적인 사건들의 연속 확률
각 실험이 하나 뒤에 다른 하나가 발생하는 두 독립 사건을 포함할 때, 독립적인 사건들의 연속 확률 계산기를 사용하여 확률을 결정할 수 있습니다. 이 계산기에서는 사건이 발생하는 횟수를 설정해야 합니다.
정규 분포의 확률
정규 분포 확률 계산기는 정규 곡선의 확률을 결정하는 데 도움이 됩니다. 평균 μ, 표준 편차 σ, 그리고 경계를 입력해야 합니다. 정규 확률 계산기는 설정된 경계의 확률과 다양한 신뢰 수준의 범위에 대한 신뢰 구간을 생성할 것입니다.
확률 소개
확률은 사건이 발생할 기회입니다. 사건이 확실히 발생할 때, 그 확률은 1입니다. 사건이 발생하지 않을 때, 그 확률은 0입니다. 결과적으로, 주어진 사건의 확률은 항상 0과 1 사이입니다. 확률 계산기는 다양한 사건의 확률을 계산하는 것을 놀랍도록 간단하게 만듭니다.
사건 연산 규칙
실험 결과의 어떤 그룹화도 사건으로 언급됩니다. 그것은 샘플 공간의 어떤 부분 집합이 될 수 있는 사건입니다. 보완, 교집합, 합집합은 사건 연산의 규칙으로 식별될 수 있습니다. 아래 예를 사용하여 이러한 각 규칙을 알아봅시다.
예제
당신의 대학에는 비즈니스 학부를 포함한 다양한 학부가 있습니다. 국제 학생들도 이 대학에 등록되어 있습니다. 프로젝트의 일환으로 당신의 대학생들과 인터뷰를 진행해야 합니다. 당신은 문을 통해 들어오는 첫 번째 학생으로 시작하기로 결정했습니다. 다음과 같은 확률을 알고 있습니다. 가정해 봅시다,
A = 첫 번째 학생이 비즈니스 학부 출신이다.
B = 첫 번째 학생이 국제 학생이다.
P(A) = 0.6
P(B) = 0.3
사건의 보완
사건의 보완은 샘플 공간 내에서 해당 사건에 포함되지 않은 모든 결과의 집합입니다.
예를 들어, 사건 A의 보완은 첫 번째 학생이 비즈니스 학부가 아닌 다른 곳 출신임을 의미합니다. 이는 \$A\prime\$ 또는 Aᶜ로 표시될 수 있습니다.
사건 A의 보완을 벤 다이어그램으로 보여줍시다.
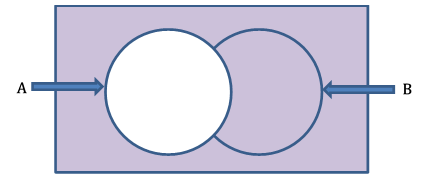
위의 벤 다이어그램에서, 색칠된 영역은 사건 A의 보완을 나타냅니다.
사각형의 전체 면적은 샘플 공간의 전체 확률을 나타냅니다. 정확히 하나입니다. 원 A 외부의 공간은 사건 A의 보완의 확률을 보여줍니다. 벤 다이어그램을 통해 다음과 같은 관계를 설정할 수 있습니다:
$$P\left(A\right)+P\left(A^\prime\right)=1$$
따라서,
$$P\left(A^\prime\right)=1-P\left(A\right)$$
다음 확률을 찾아봅시다.
인터뷰를 위해 선택하는 첫 번째 학생이 비즈니스 학부 출신이 아닌 확률:
$$P\left(A^\prime\right)=1-P\left(A\right)=1-0.6=0.4$$
인터뷰를 위해 선택하는 첫 번째 학생이 국제 학생이 아닌 확률:
$$P\left(B^\prime\right)=1-P\left(B\right)=1-0.3=0.7$$
사건의 교집합
두 사건 A와 B의 교집합은 사건 A와 B 모두에 속하는 모든 공통 요소의 목록입니다. "AND"라는 단어는 종종 두 집합의 교집합을 나타내기 위해 사용됩니다.
예제 1에서 사건 A와 사건 B의 교집합은 국제 학생을 선택하며, 그 학생이 비즈니스 학부 출신임을 의미합니다. 다음과 같이 표기할 수 있습니다:
$$A\cap B$$
사건 A와 B의 교집합을 벤 다이어그램으로 보여줍시다.
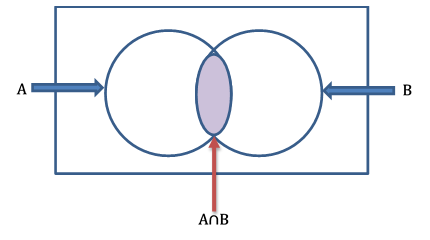
위의 벤 다이어그램에서, 색칠된 영역은 사건 A와 B의 교집합을 나타냅니다.
인터뷰를 위해 지역 학생을 선택하는 사건을 C라고 가정해 봅시다. 이제 사건 A와 C를 벤 다이어그램으로 보여주겠습니다.
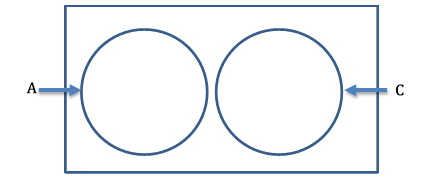
국제 학생과 지역 학생을 동시에 선택할 수 없습니다. 만약 첫 번째로 선택한 학생이 국제 학생이라면, 그것은 첫 번째 학생이 지역 학생인 사건을 배제합니다. 따라서, 사건 A와 C는 상호 배타적인 사건입니다.
상호 배타적인 사건들 사이에는 공통 요소가 없습니다. 따라서, 두 상호 배타적인 사건의 교집합은 공집합입니다.
$$A\cap C=φ$$
사건의 교집합 확률은 다양한 방법으로 계산될 수 있습니다. 사건 A와 B는 다음과 같이 쓸 수 있습니다.
$$P\left(A\cap B\right)=P\left(A\right)+P\left(B\right)-P\left(A\cup B\right)$$
$$P\left(A\cap B\right)=P(A)× P(B/A)$$
$$P\left(A\cap B\right)=P(B)× P(A/B)$$
독립 사건
독립 사건은 서로에게 영향을 주지 않는 사건들입니다. 우리 예제에서, 비즈니스 학부의 학생을 선택하는 것은 국제 학생을 선택하는 것에 영향을 주지 않습니다. 따라서, 사건 A와 사건 B는 두 개의 독립 사건이라고 할 수 있습니다.
사건들이 독립적일 때, 그 중 어느 하나가 발생할 확률은 다른 사건의 확률에 의존하지 않습니다. 따라서,
$$P(B/A)=B\ 그리고\ P(A/B)=A$$
이 공식들을 사용하여 이전에 배운 공식을 수정하여 두 교집합 사건의 확률을 결정할 수 있습니다.
$$P\left(A\cap B\right)=P\left(A\right)× P\left(\mathrm{B/A}\right)P\left(A\cap B\right)=P(A)× P(B)$$
$$P\left(A\cap B\right)=P\left(B\right)× P\left(\mathrm{A/B}\right)P\left(A\cap B\right)=P(B)× P(A)$$
따라서, 두 독립 사건의 교집합을 찾기 위해 그 두 사건의 확률을 곱할 수 있습니다.
$$P\left(A\cap B\right)=P\left(A\right)× P\left(B\right)=P(B)× P(A)$$
사건 A와 B가 독립적이라고 가정할 때, 인터뷰를 위해 선택한 첫 번째 학생이 비즈니스 학부 출신이면서 국제 학생일 확률을 결정합시다.
$$P\left(A\cap B\right)=P\left(A\right)× P\left(B\right)=0.6× 0.3=0.18$$
사건의 합집합
두 사건의 합집합은 양쪽 사건에서 모든 요소를 포함하는 다른 사건을 생성합니다. "OR"이라는 단어는 통상적으로 두 사건의 합집합을 설명하는 데 사용됩니다.
예제 1에서, 사건 A와 B의 합집합은 국제 학생 또는 비즈니스 학부의 학생을 선택하는 것을 의미합니다. 이는 다음과 같이 표기될 수 있습니다.
$$A\cup B$$
사건 A와 B의 합집합을 벤 다이어그램으로 보여줍시다.
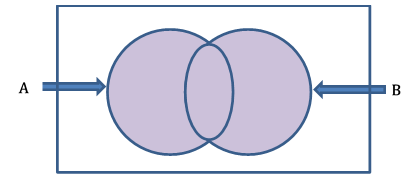
위의 벤 다이어그램에서 색칠된 영역은 사건 A와 B의 합집합을 나타냅니다.
사건 A 또는 사건 B의 확률을 계산하려면, 두 사건의 확률을 더하고 교집합의 확률을 빼야 합니다.
사건 A와 B의 합집합의 확률은 다음과 같이 쓸 수 있습니다.
$$P\left(A\cup B\right)=P\left(A\right)+P\left(B\right)-P\left(A\cap B\right)$$
위의 공식을 수정하여 두 사건의 교집합 확률이 알려지지 않았고 두 사건이 독립적일 때 두 독립 사건의 합집합 확률을 찾는 새로운 공식을 만들 수 있습니다.
사건이 독립적이라면,
$$P\left(A\cap B\right)=P(A)× P(B)$$
따라서,
$$P\left(A\cup B\right)=P\left(A\right)+P\left(B\right)-P(A)× P(B)$$
사건 A와 B를 결합할 확률을 계산해 봅시다. 즉, 비즈니스 전공자이면서 국제 학생이거나 둘 모두인 학생을 선택할 확률은 얼마일까요?
$$P(A\cup B)=P(A)+P(B)-P(A\cap B)=0.6+0.3-0.18=0.72$$
두 사건의 확률 계산기 또는 두 사건에 대한 확률 해결기 계산기 덕분에 위의 모든 계산을 신속하게 완료할 수 있습니다. 확률 계산 단계를 확인하고 싶다면, 계산 단계를 표시하기 때문에 두 사건에 대한 확률 해결기 계산기를 사용할 수도 있습니다.
정규 분포
정규 분포는 대칭적이며 종 모양을 가집니다. 정규 분포는 평균, 중앙값, 최빈값이 동일하며 데이터의 50%는 평균 이상이고 50%는 평균 이하입니다. 정규 분포 곡선은 양쪽 방향으로 평균에서 멀어지지만 X축을 절대 닿지 않습니다. 곡선 아래의 전체 면적은 1입니다.
랜덤 변수 X가 μ와 σ²의 매개변수를 가진 정규 분포를 가질 때, 우리는 *X ~ N(μ, σ²)*라고 씁니다.
정규 분포의 확률
정규 분포의 확률 밀도 함수는 아래와 같습니다:
$$f\left(x\right)=\frac{1}{\sqrt{2π\sigma^2}}× e^\frac{-{(x-\mu)}^2}{2\sigma^2}$$
이 함수에서:
- μ는 분포의 평균입니다;
- σ²는 분포의 분산입니다;
- π는 3.14입니다;
- e는 2.7182입니다.
평균과 표준 편차의 각 조합에 대한 확률 테이블을 제공하는 것은 불가능합니다. 왜냐하면 다양한 정규 곡선이 무한히 많기 때문입니다. 결과적으로 표준 정규 분포가 사용됩니다. 평균이 0이고 표준 편차가 1인 정규 분포를 표준 정규 분포라고 합니다.
정규 분포의 확률을 계산하기 위해서는 먼저 z-점수를 사용하여 실제 분포를 표준 정규 분포로 변환한 다음 z-테이블을 사용하여 확률을 계산해야 합니다. 정규 확률 계산기는 다양한 신뢰 수준에 대한 확률을 제공함으로써 표준 정규 확률 계산기 역할을 합니다.
$$Z=\frac{X-\mu}{\sigma}$$
표준 정규 분포 곡선은 다양한 실세계 문제를 해결하는 데 사용될 수 있습니다. 연속 변수의 확률을 결정하는 데 정규 분포가 사용됩니다. 연속 변수는 소수점을 포함한 모든 값을 가질 수 있는 변수입니다. 연속 변수의 몇 가지 예는 키, 체중, 온도 등입니다.
아래 예제를 통해 정규 분포의 확률을 찾는 방법을 배워봅시다.
예제
당신의 배치 통계 강의 결과는 평균이 65이고 표준 편차가 10인 정규 분포를 따릅니다. 무작위로 학생을 선택할 경우 다음 시나리오의 확률을 결정하세요:
- 학생의 점수가 70 이상일 확률,
- 학생의 점수가 70 미만일 확률,
- 학생의 점수가 50과 70 사이일 확률.
해결
$$P\left(X≥70\right)=P\left(Z≥\frac{70-65}{10}\right)=P\left(Z≥0.5\right)=1-0.6915=0.3085$$
$$P\left(X<70\right)=P\left(Z<\frac{70-65}{10}\right)=P\left(Z<0.5\right)=0.6915$$
$$P\left(50>X>70\right)=P\left(\frac{50-65}{10}>Z>\frac{70-65}{10}\right)=P\left(1.5>Z>0.5\right)=0.4332+0.1915=0.6247$$
정규 곡선의 확률을 계산하는 것은 많은 단계를 필요로하며 z-테이블을 사용해야 합니다. 반면, 정규 분포 확률 계산기를 사용하면 계산기에 네 개의 숫자만 입력하여 간단하게 확률을 계산할 수 있습니다. 정규 분포 계산기를 사용하려면 평균, 표준 편차, 그리고 좌우 경계만 입력하면 됩니다.