Geen resultaten gevonden
We kunnen momenteel niets met die term vinden, probeer iets anders te zoeken.
Z-Score Rekenmachine
De Z-Score Rekenmachine helpt bij het verkrijgen van de z-score van een normale verdeling, het omzetten tussen z-score en waarschijnlijkheid, en het bepalen van de waarschijnlijkheid tussen 2 z-scores.
| Resultaat | ||
|---|---|---|
| Z-score | 1 | |
| Waarschijnlijkheid van x<5 | 0.84134 | |
| Waarschijnlijkheid van x>5 | 0.15866 | |
| Waarschijnlijkheid van 3<x<5 | 0.34134 | |
| Resultaat | ||
|---|---|---|
| Z-score | 2 | |
| P(x<Z) | 0.97725 | |
| P(x>Z) | 0.02275 | |
| P(0<x<Z) | 0.47725 | |
| P(-Z<x<Z) | 0.9545 | |
| P(x<-Z or x>Z) | 0.0455 | |
| Resultaat | ||
|---|---|---|
| P(-1<x<0) | 0.34134 | |
| P(x<-1 or x>0) | 0.65866 | |
| P(x<-1) | 0.15866 | |
| P(x>0) | 0.5 | |
Er was een fout met uw berekening.
Inhoudsopgave
- Wat is z-score?
- De Z-Score formule
- Interpretatie van de resultaten van de verkregen Z-score
- Z-score en standaarddeviatie
- Z-score en de normale verdeling
- Vergelijking van datapunten
- Data normalisatie
- Hypothesetesting
- Kenmerkschaling
- Voorspellende modellering
- Gebruik van de Z-score tabel
- De waarschijnlijkheid vinden vanuit Z-score
- De Overeenkomstige Waarden Vinden voor de Gespecificeerde Waarschijnlijkheid

De Z-Score Rekenmachine kan worden gebruikt voor elk type berekening gerelateerd aan Z-Scores. Je kunt een ruwe score (X), Gemiddelde van de populatie (μ) en Standaardafwijking (σ) invoeren in de eerste rekenmachine om de Z-Score met stappen en gerelateerde waarschijnlijkheden voor die ruwe score te vinden.
De Z-score en Waarschijnlijkheidsomzetter helpt je om te converteren tussen Z-Scores en waarschijnlijkheden zonder een Z-tabel te raadplegen. De resultaten zullen alle mogelijke waarschijnlijkheidsberekeningen met die enkele z-score omvatten. Gebruik de laatste rekenmachine om de waarschijnlijkheid tussen 2 Z-Scores te vinden.
Wat is z-score?
Z-score is een statistische maat die het aantal standaardafwijkingen van een datapunt van het gemiddelde van een gegevensset beschrijft. De Z-score wordt gebruikt om een enkel datapunt te vergelijken met de gehele gegevensset en helpt om de gegevens te standaardiseren, zodat ze gemakkelijker te vergelijken en te analyseren zijn.
De Z-score stelt ons in staat te bepalen hoe "typisch" of omgekeerd "atypisch" een enkel datapunt is in vergelijking met de gehele gegevensset.
- Detecteren van uitschieters: Z-scores kunnen ons helpen datapunten te identificeren die aanzienlijk verschillen van de rest van de gegevens. Dit is nuttig in gebieden zoals financiën en medisch onderzoek, waar uitschieters belangrijke patronen of anomalieën kunnen aangeven.
- Gegevens vergelijken uit verschillende sets: Z-score stelt ons in staat om gegevens uit verschillende sets te vergelijken, zelfs als ze verschillende eenheden of bereiken hebben. Dit is nuttig in gebieden zoals machine learning, waar je gegevens uit verschillende bronnen moet vergelijken om modellen te bouwen.
- Normaliseren van gegevens: Door gegevens om te zetten in Z-scores, kunnen we gegevens standaardiseren en ze gemakkelijker vergelijken en analyseren. Dit is nuttig in gebieden zoals gegevensvisualisatie, waar we gegevens op een begrijpelijke manier moeten presenteren.
De Z-Score formule
De Z-Score voor een populatie
Z = Ruwe score - Gemiddelde van de populatie / Standaardafwijking van de populatie
Z = (X - μ) / σ
De Z-Score voor een steekproef
Z = Ruwe score - Gemiddelde van de steekproef / Standaardafwijking van de steekproef
Z = (X - x̄) / s
Interpretatie van de resultaten van de verkregen Z-score
Positieve Z-score: Een positieve Z-score betekent dat je datapunt boven de gemiddelde waarde van de gegevensset ligt. Met andere woorden, je waargenomen datapunt is hoger dan de typische waarde in de gegevensset.
Negatieve Z-score: Een negatieve Z-score betekent dat je datapunt onder de gemiddelde waarde van de gegevensset ligt. Met andere woorden, je waargenomen datapunt is lager dan de typische waarde in de gegevensset.
Z-score: De Z-score vertelt je hoe ver je datapunt van het gemiddelde van de gegevensset af ligt. Hoe groter de Z-score, hoe verder je waargenomen datapunt van de gemiddelde waarde af ligt.
Z-score en standaarddeviatie
Z-score en standaarddeviatie zijn gerelateerd omdat de standaarddeviatie wordt gebruikt om de Z-score te berekenen. De standaarddeviatie is in feite een sleutelcomponent van de Z-scoreformule.
De standaarddeviatie is een maat voor de spreiding van de gegevensset. Het laat zien hoe ver elk datapunt afwijkt van de gemiddelde waarde van de gegevensset. Hoe groter de standaarddeviatie, hoe groter de spreiding van de gegevens.
De Z-score daarentegen vertelt je hoe ver een datapunt van de gemiddelde waarde van de gegevensset af ligt in verhouding tot de standaarddeviatie. Door de standaarddeviatie te gebruiken om de Z-score te berekenen, kun je een datapunt vergelijken met de gehele gegevensset en zien hoe ongebruikelijk of typisch het is.
Z-score en de normale verdeling
De normale verdeling is een type verdeling dat vaak voorkomt in veel reële fenomenen. Het is een klokvormige curve die de verdeling van gegevens rond het gemiddelde van een gegevensset vertegenwoordigt. De normale verdeling staat ook bekend als de Gauss-verdeling, naar de wiskundige Carl Friedrich Gauss.
De Z-score is een manier om te meten hoe ver een datapunt van het gemiddelde van een gegevensset af ligt in verhouding tot de standaarddeviatie. Door elk datapunt om te zetten in een Z-score, kun je een individueel datapunt vergelijken met de gehele gegevensset en zien hoe ongebruikelijk of typisch het is.
Het verband tussen een Z-score en een normale verdeling is dat de Z-score kan worden gebruikt om de gegevens te standaardiseren en aan te passen aan een normale verdeling. Dit betekent dat je elke gegevensset kunt omzetten in een normale verdeling door elk datapunt om te zetten in een Z-score. Dit is nuttig omdat veel statistische methoden ervan uitgaan dat de gegevens normaal verdeeld zijn, dus het omzetten van de gegevens in een normale verdeling kan je helpen deze methoden nauwkeuriger te gebruiken.
Vergelijking van datapunten
Z-score kan je helpen begrijpen hoe ver een datapunt van het gemiddelde van een gegevensset af ligt in verhouding tot de standaarddeviatie.
Ons voorbeeld van het gebruik van Z-score om datapunten te vergelijken is van toepassing op financiën. Stel, je hebt geïnvesteerd in twee verschillende aandelenportefeuilles en wilt hun prestaties vergelijken. Het gemiddelde rendement van portefeuille A is 10% met een standaarddeviatie van 2%, en het gemiddelde rendement van portefeuille B is 8% met een standaarddeviatie van 3%. Door de rendementen om te zetten in Z-scores, kun je de rendementen van elke portefeuille vergelijken en bepalen welke beter presteert.
Een ander praktisch voorbeeld van het gebruik van Z-score om datapunten te vergelijken is sport. Stel, je wilt de prestaties van twee basketbalspelers vergelijken, speler A en speler B. Speler A scoort gemiddeld 20 punten per wedstrijd met een standaarddeviatie van 5 punten, en speler B scoort gemiddeld 18 punten per wedstrijd met een standaarddeviatie van 3 punten. Door de scores om te zetten in Z-scores, kun je de prestaties van elke speler vergelijken en bepalen welke speler beter presteert.
Data normalisatie
Data normalisatie is het proces van het omzetten van gegevens naar een standaardschaal, zodat deze gemakkelijk vergeleken en geanalyseerd kunnen worden. Dit is belangrijk omdat gegevens verschill
ende vormen en schalen kunnen hebben, en het normaliseren van gegevens zorgt ervoor dat ze op dezelfde schaal staan en gemakkelijker te vergelijken en te analyseren zijn.
Door elk datapunt om te zetten in een Z-score, kun je de gegevens standaardiseren en op dezelfde schaal zetten. Dit komt omdat de Z-score altijd op een standaardschaal staat, waarbij het gemiddelde 0 is en de standaarddeviatie 1.
Een praktisch voorbeeld van het gebruik van Z-score om gegevens te normaliseren heeft betrekking op het gebied van psychologie. Stel, je wilt de resultaten van twee IQ-tests vergelijken, Test A en Test B. Test A heeft een gemiddelde score van 100 met een standaarddeviatie van 15, en Test B heeft een gemiddelde score van 110 met een standaarddeviatie van 10. Door de scores om te zetten in Z-scores, kunnen de scores worden gestandaardiseerd en teruggebracht naar een enkele schaal, wat vergelijking en analyse vergemakkelijkt.
Een ander praktisch voorbeeld van het gebruik van Z-score om gegevens te normaliseren is in het onderwijs. Stel, je wilt de cijfers van twee studenten vergelijken, student A en student B. Student A heeft een gemiddeld cijfer van 80 met een standaarddeviatie van 5, en student B heeft een gemiddeld cijfer van 90 met een standaarddeviatie van 3. Door de cijfers om te zetten in Z-coëfficiënten, kun je de cijfers standaardiseren en ze allemaal op dezelfde schaal zetten, wat vergelijking en analyse gemakkelijker maakt.
Hypothesetesting
Hypothesetesting is een statistische techniek die wordt gebruikt om te bepalen of er voldoende bewijs is om de nulhypothese te verwerpen, of de standaardaanname dat er geen relatie is tussen twee variabelen. Dit is belangrijk in vele velden, waaronder medisch onderzoek, sociale wetenschappen en bedrijfsleven, waar het nemen van geïnformeerde beslissingen op basis van gegevens cruciaal is.
Bij het testen van hypothesen kunnen Z-coëfficiënten worden gebruikt om de waarschijnlijkheid van een bepaalde uitkomst te bepalen. Bijvoorbeeld, je zou kunnen testen of het gemiddelde gewicht van een groep mensen verschilt van het gemiddelde gewicht van de gehele bevolking. Je kunt de Z-score gebruiken om te bepalen of het verschil statistisch significant is.
Een praktisch voorbeeld van het gebruik van de Z-score om hypothesen te testen is in de medische sector. Bijvoorbeeld, je wilt testen of een nieuw medicijn effectief is in het verminderen van de symptomen van een bepaalde ziekte. Je kunt de Z-score gebruiken om te bepalen of het verschil in symptomen tussen de groep die het medicijn neemt en de controlegroep statistisch significant is.
Een ander praktisch voorbeeld van het gebruik van de Z-score om hypothesen te testen is op het gebied van financiën. Bijvoorbeeld, je wilt testen of een bepaald aandeel een hoger rendement heeft dan het gemiddelde aandeel op de markt. Je kunt de Z-score gebruiken om te bepalen of het verschil in rendementen statistisch significant is.
Kenmerkschaling
Kenmerkschaling is een techniek die wordt gebruikt in machine learning en andere data-analyse toepassingen om ervoor te zorgen dat alle kenmerken in een dataset dezelfde schaal hebben. Dit is belangrijk omdat sommige machine learning-algoritmen gevoelig zijn voor de schaal van de gegevens en onnauwkeurige resultaten kunnen produceren als de schaal niet overeenkomt.
Een gangbare methode voor het schalen van kenmerken is Z-score normalisatie, ook bekend als standaardisatie. In dit proces wordt elk kenmerk omgezet zodat de gemiddelde waarde 0 is en de standaardafwijking 1. De formule voor het berekenen van de Z-score van een kenmerk is als volgt:
Z = (X - Gemiddelde) / Standaarddeviatie
waar X de waarde van het kenmerk is, Gemiddelde is het gemiddelde van het kenmerk, en Standaarddeviatie is de Standaarddeviatie van het kenmerk.
Een praktisch voorbeeld van het gebruik van Z-score voor kenmerkschaling is op het gebied van computer vision. Bij het werken met beelddata is het meestal nodig om pixelwaarden te schalen zodat ze in het bereik van 0 tot 1 liggen. Dit kan worden bereikt door normalisatie van de Z-score, aangezien elke pixelwaarde kan worden getransformeerd zodat de gemiddelde waarde 0 is, en de standaardafwijking 1.
Een ander praktisch voorbeeld van het gebruik van Z-score voor kenmerkschaling is natuurlijke taalverwerking. Bij het werken met tekstuele gegevens is het gebruikelijk om termfrequentie en inverse documentfrequentie (TF-IDF) waarden te schalen zodat ze in het bereik van 0 tot 1 liggen. Dit kan ook worden bereikt door gebruik te maken van Z-score normalisatie.
Voorspellende modellering
Voorspellende modellering is een techniek die wordt gebruikt in machine learning en andere data-analyse toepassingen om voorspellingen te maken op basis van historische gegevens. Het omvat het trainen van een model op een dataset en het gebruik van dat model om voorspellingen te maken op nieuwe, ongeziene gegevens.
Een belangrijk aspect van voorspellende modellering is kenmerkselectie, wat inhoudt dat de meest relevante kenmerken uit de dataset worden geselecteerd voor gebruik in het model. Vaak worden kenmerken die sterk gecorreleerd zijn met de doelvariabele verkozen omdat ze waarschijnlijker de doelvariabele voorspellen.
De Z-score kan worden gebruikt om kenmerken te identificeren die sterk gecorreleerd zijn met de doelvariabele omdat kenmerken met een hoge Z-score waarschijnlijker de doelvariabele voorspellen. De formule voor het berekenen van de Z-score van een kenmerk is als volgt:
Z = (X - Gemiddelde) / Standaarddeviatie
waar X de waarde van het kenmerk is, Gemiddelde is het gemiddelde van het kenmerk, en Standaarddeviatie is de Standaarddeviatie van het kenmerk.
Een praktisch voorbeeld van het gebruik van Z-score in prognostische modellering behoort tot het gebied van financiën. Bij het voorspellen van aandelenkoersen kan de Z-score van de eerdere prestaties van het aandeel worden gebruikt om het toekomstige rendementspotentieel te bepalen. Een hoge Z-score geeft aan dat het eerdere rendement van een aandeel ruim boven het gemiddelde ligt en kan worden geprojecteerd voor hogere rendementen in de toekomst.
Een ander praktisch voorbeeld van het gebruik van de Z-score in voorspellende modellering is op het gebied van gezondheidszorg. Bij het voorspellen van patiëntenuitkomsten kan de Z-score worden gebruikt om het potentieel van een patiënt voor toekomstige uitkomsten te bepalen. Een hoge Z-score geeft aan dat de gezondheidsuitkomsten van een patiënt aanzienlijk slechter zijn dan het gemiddelde en kan wijzen op slechte toekomstige uitkomsten.
Gebruik van de Z-score tabel
Een Z-tabel, ook bekend als een standaard normale tabel of eenheidsnormale tabel, is een tabel die gestandaardiseerde waarden bevat die worden gebruikt om de waarschijnlijkheid te berekenen van een gegeven statistiek die onder, boven of tussen de standaard normale verdeling valt.
| z | 0 | 0,01 | 0,02 | 0,03 | 0,04 | 0,05 | 0,06 | 0,07 | 0,08 | 0,09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0,00399 | 0,00798 | 0,01197 | 0,01595 | 0,01994 | 0,02392 | 0,0279 | 0,03188 | 0,03586 |
| 0,1 | 0,03983 | 0,0438 | 0,04776 | 0,05172 | 0,05567 | 0,05962 | 0,06356 | 0,06749 | 0,07142 | 0,07535 |
| 0,2 | 0,07926 | 0,08317 | 0,08706 | 0,09095 | 0,09483 | 0,09871 | 0,10257 | 0,10642 | 0,11026 | 0,11409 |
| 0,3 | 0,11791 | 0,12172 | 0,12552 | 0,1293 | 0,13307 | 0,13683 | 0,14058 | 0,14431 | 0,14803 | 0,15173 |
| 0,4 | 0,15542 | 0,1591 | 0,16276 | 0,1664 | 0,17003 | 0,17364 | 0,17724 | 0,18082 | 0,18439 | 0,18793 |
| 0,5 | 0,19146 | 0,19497 | 0,19847 | 0,20194 | 0,2054 | 0,20884 | 0,21226 | 0,21566 | 0,21904 | 0,2224 |
| 0,6 | 0,22575 | 0,22907 | 0,23237 | 0,23565 | 0,23891 | 0,24215 | 0,24537 | 0,24857 | 0,25175 | 0,2549 |
| 0,7 | 0,25804 | 0,26115 | 0,26424 | 0,2673 | 0,27035 | 0,27337 | 0,27637 | 0,27935 | 0,2823 | 0,28524 |
| 0,8 | 0,28814 | 0,29103 | 0,29389 | 0,29673 | 0,29955 | 0,30234 | 0,30511 | 0,30785 | 0,31057 | 0,31327 |
| 0,9 | 0,31594 | 0,31859 | 0,32121 | 0,32381 | 0,32639 | 0,32894 | 0,33147 | 0,33398 | 0,33646 | 0,33891 |
| 1 | 0,34134 | 0,34375 | 0,34614 | 0,34849 | 0,35083 | 0,35314 | 0,35543 | 0,35769 | 0,35993 | 0,36214 |
| 1,1 | 0,36433 | 0,3665 | 0,36864 | 0,37076 | 0,37286 | 0,37493 | 0,37698 | 0,379 | 0,381 | 0,38298 |
| 1,2 | 0,38493 | 0,38686 | 0,38877 | 0,39065 | 0,39251 | 0,39435 | 0,39617 | 0,39796 | 0,39973 | 0,40147 |
| 1,3 | 0,4032 | 0,4049 | 0,40658 | 0,40824 | 0,40988 | 0,41149 | 0,41308 | 0,41466 | 0,41621 | 0,41774 |
| 1,4 | 0,41924 | 0,42073 | 0,4222 | 0,42364 | 0,42507 | 0,42647 | 0,42785 | 0,42922 | 0,43056 | 0,43189 |
| 1,5 | 0,43319 | 0,43448 | 0,43574 | 0,43699 | 0,43822 | 0,43943 | 0,44062 | 0,44179 | 0,44295 | 0,44408 |
| 1,6 | 0,4452 | 0,4463 | 0,44738 | 0,44845 | 0,4495 | 0,45053 | 0,45154 | 0,45254 | 0,45352 | 0,45449 |
| 1,7 | 0,45543 | 0,45637 | 0,45728 | 0,45818 | 0,45907 | 0,45994 | 0,4608 | 0,46164 | 0,46246 | 0,46327 |
| 1,8 | 0,46407 | 0,46485 | 0,46562 | 0,46638 | 0,46712 | 0,46784 | 0,46856 | 0,46926 | 0,46995 | 0,47062 |
| 1,9 | 0,47128 | 0,47193 | 0,47257 | 0,4732 | 0,47381 | 0,47441 | 0,475 | 0,47558 | 0,47615 | 0,4767 |
| 2 | 0,47725 | 0,47778 | 0,47831 | 0,47882 | 0,47932 | 0,47982 | 0,4803 | 0,48077 | 0,48124 | 0,48169 |
| 2,1 | 0,48214 | 0,48257 | 0,483 | 0,48341 | 0,48382 | 0,48422 | 0,48461 | 0,485 | 0,48537 | 0,48574 |
| 2,2 | 0,4861 | 0,48645 | 0,48679 | 0,48713 | 0,48745 | 0,48778 | 0,48809 | 0,4884 | 0,4887 | 0,48899 |
| 2,3 | 0,48928 | 0,48956 | 0,48983 | 0,4901 | 0,49036 | 0,49061 | 0,49086 | 0,49111 | 0,49134 | 0,49158 |
| 2,4 | 0,4918 | 0,49202 | 0,49224 | 0,49245 | 0,49266 | 0,49286 | 0,49305 | 0,49324 | 0,49343 | 0,49361 |
| 2,5 | 0,49379 | 0,49396 | 0,49413 | 0,4943 | 0,49446 | 0,49461 | 0,49477 | 0,49492 | 0,49506 | 0,4952 |
| 2,6 | 0,49534 | 0,49547 | 0,4956 | 0,49573 | 0,49585 | 0,49598 | 0,49609 | 0,49621 | 0,49632 | 0,49643 |
| 2,7 | 0,49653 | 0,49664 | 0,49674 | 0,49683 | 0,49693 | 0,49702 | 0,49711 | 0,4972 | 0,49728 | 0,49736 |
| 2,8 | 0,49744 | 0,49752 | 0,4976 | 0,49767 | 0,49774 | 0,49781 | 0,49788 | 0,49795 | 0,49801 | 0,49807 |
| 2,9 | 0,49813 | 0,49819 | 0,49825 | 0,49831 | 0,49836 | 0,49841 | 0,49846 | 0,49851 | 0,49856 | 0,49861 |
| 3 | 0,49865 | 0,49869 | 0,49874 | 0,49878 | 0,49882 | 0,49886 | 0,49889 | 0,49893 | 0,49896 | 0,499 |
| 3,1 | 0,49903 | 0,49906 | 0,4991 | 0,49913 | 0,49916 | 0,49918 | 0,49921 | 0,49924 | 0,49926 | 0,49929 |
| 3,2 | 0,49931 | 0,49934 | 0,49936 | 0,49938 | 0,4994 | 0,49942 | 0,49944 | 0,49946 | 0,49948 | 0,4995 |
| 3,3 | 0,49952 | 0,49953 | 0,49955 | 0,49957 | 0,49958 | 0,4996 | 0,49961 | 0,49962 | 0,49964 | 0,49965 |
| 3,4 | 0,49966 | 0,49968 | 0,49969 | 0,4997 | 0,49971 | 0,49972 | 0,49973 | 0,49974 | 0,49975 | 0,49976 |
| 3,5 | 0,49977 | 0,49978 | 0,49978 | 0,49979 | 0,4998 | 0,49981 | 0,49981 | 0,49982 | 0,49983 | 0,49983 |
| 3,6 | 0,49984 | 0,49985 | 0,49985 | 0,49986 | 0,49986 | 0,49987 | 0,49987 | 0,49988 | 0,49988 | 0,49989 |
| 3,7 | 0,49989 | 0,4999 | 0,4999 | 0,4999 | 0,49991 | 0,49991 | 0,49992 | 0,49992 | 0,49992 | 0,49992 |
| 3,8 | 0,49993 | 0,49993 | 0,49993 | 0,49994 | 0,49994 | 0,49994 | 0,49994 | 0,49995 | 0,49995 | 0,49995 |
| 3,9 | 0,49995 | 0,49995 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49997 | 0,49997 |
| 4 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49998 | 0,49998 | 0,49998 | 0,49998 |
Om de Z-tabel te gebruiken, moet je de rij vinden die overeenkomt met jouw berekende Z-score en vervolgens de overeenkomstige kolom lokaliseren die het gebied (waarschijnlijkheid) onder de standaard normale curve geeft. De resulterende waarde is de benaderde waarschijnlijkheid dat een willekeurige variabele uit een standaard normale verdeling kleiner dan of gelijk aan jouw berekende Z-score zal zijn.
Bijvoorbeeld, als je een Z-score van 1,96 hebt, zou je in de Z-tabel kijken naar de rij die overeenkomt met 1,9 en de kolom die overeenkomt met 0,06. De resulterende waarde geeft je het gebied onder de standaard normale curve rechts van 1,96. Deze waarde is ongeveer 0,975, wat betekent dat ongeveer 97,5% van de gegevens uit een standaard normale verdeling kleiner dan of gelijk aan 1,96 zal zijn.
Het is belangrijk om op te merken dat de Z-tabel alleen werkt voor een standaard normale verdeling met een gemiddelde van 0 en een standaarddeviatie van 1. Als jouw gegevens deze verdeling niet volgen, moet je ze eerst standaardiseren door de gegevens om te zetten in Z-scores.
De waarschijnlijkheid vinden vanuit Z-score
Wanneer we een normaal verdeelde variabele omzetten in een Z-score, kunnen we de Z-scoretabel gebruiken en de proportie van het gebied onder de normale curve vinden. De totale oppervlakte onder de standaard normale curve is gelijk aan 1. Daarom is de proportie van het gebied dat bedekt wordt in een normale curve gelijk aan de waarschijnlijkheid van die Z-score.
Voorbeeld 1
De gewichten van boksspelers zijn normaal verdeeld met een gemiddelde van 75 kg en een standaarddeviatie van 3 kg. Wat is de waarschijnlijkheid dat het gewicht van een willekeurig geselecteerde speler is;
- a) Meer dan 78 kg?
- b) Minder dan 69 kg?
- c) Meer dan 72 kg?
- d) Minder dan 79,5 kg?
- e) Tussen 72 kg en 76,5 kg?
- f) Tussen 72 kg en 73,5 kg?
a) Wat is de waarschijnlijkheid dat een willekeurig geselecteerde speler meer dan 78 kg weegt?
- X > 78
- μ = 75
- σ = 3
$$P(X>78)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{78-75}{3}\right)=P(Z>1)$$
Eerst zullen we dit tekenen in een Z-curve.
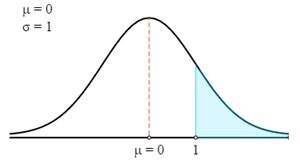
Nu zullen we de Z-tabel gebruiken om de relevante waarschijnlijkheid voor de berekende Z-Score te vinden.
Onthoud dat Z-Score altijd de waarschijnlijkheid geeft tussen de Z-score en het gemiddelde. Om de waarschijnlijkheid van het gemarkeerde gebied in de grafiek te krijgen, moeten we die waarschijnlijkheid van 0,5 aftrekken. (Totale waarschijnlijkheid onder de curve is 1, en het gemiddelde van de standaardverdeling scheidt gelijkmatig in 2 delen. Dus, de waarschijnlijkheid van het gemiddelde punt naar beide uiteinden is 0,5.)
- P (X > 78) = P (Z > 1)
- P (X > 78) = 0,5 - P(0 < Z < 1)
- P (X > 78) = 0,5 - 0,3413
- P (X > 78) = 0,1587
Daarom is er een waarschijnlijkheid van 0,1587 dat het gewicht van een willekeurig geselecteerde speler meer dan 78 kg is.
b) Wat is de waarschijnlijkheid dat een willekeurig geselecteerde speler minder dan 69 kg weegt?
- X < 69
- μ = 75
- σ = 3
$$P(X<69)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{69-75}{3}\right)=P(Z<-2)$$
Eerst zullen we dit tekenen in een Z-curve.
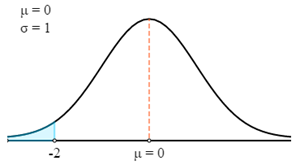
Nu zullen we de Z-tabel gebruiken om de relevante waarschijnlijkheid voor de berekende Z-Score te vinden.
Onthoud dat Z-Score altijd de waarschijnlijkheid geeft tussen de Z-score en het gemiddelde. Om de waarschijnlijkheid van het gemarkeerde gebied in de grafiek te krijgen, moeten we die waarschijnlijkheid van 0,5 aftrekken.
- P (X < 69) = P (Z < -2)
- P (X < 69) = 0,5 - P (0 > Z > -2)
- P (X < 69) = 0,5 - 0,4772
- P (X < 69) = 0,0228
Daarom is er een waarschijnlijkheid van 0,0228 dat het gewicht van een willekeurig geselecteerde speler minder dan 69 kg is.
c) Wat is de waarschijnlijkheid dat het gewicht van een willekeurig geselecteerde speler tussen 72 kg en 76,5 kg is?
- 72 < X < 76,5
- μ = 75
- σ = 3
$$P(72 \lt X \lt 76,5)=P\left(\frac{X-μ}{σ} \lt Z \lt \frac{X-μ}{σ}\right)=P\left(\frac{72-75}{3} \lt Z \lt \frac{76,5-75}{3}\right)=P(-1 \lt Z \lt 0,5)$$
Eerst zullen we dit tekenen in een Z-curve.
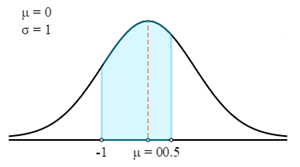
Nu zullen we de Z-tabel gebruiken om de relevante waarschijnlijkheid voor de berekende Z-Score te vinden.
Onthoud dat Z-Score altijd de waarschijnlijkheid geeft tussen de Z-score en het gemiddelde. Om de waarschijnlijkheid van het gemarkeerde gebied in de grafiek te krijgen, kun je de waarschijnlijkheden van 2 Z-scores samen optellen.
- P (72 < X < 76,5) = P (-1 < Z < 0,5)
- P (72 < X < 76,5) = 0,3413 + 0,1915
- P (72 < X < 76,5) = 0,5328
Daarom is er een waarschijnlijkheid van 0,5328 dat het gewicht van een willekeurig geselecteerde speler tussen 72 kg en 76,5 kg is.
In dit geval moet je de calculator voor de waarschijnlijkheid tussen twee Z-scores gebruiken om het antwoord snel te vinden.
De Overeenkomstige Waarden Vinden voor de Gespecificeerde Waarschijnlijkheid
Wanneer we weten dat de verdeling normaal is, kunnen we de overeenkomstige waarden vinden voor gespecificeerde waarschijnlijkheden op basis van Z-Score.
Voorbeeld 2
De cijfers van kandidaten op een competitief examen zijn bij benadering normaal verdeeld, met een gemiddelde van 55 en een standaarddeviatie van 10. Als de beste 30% van de kandidaten slaagt voor de test, vind dan de minimale slaagscore.
Oplossing
In dit geval moeten we eerst de overeenkomstige Z-score vinden voor de gegeven waarschijnlijkheid of percentage.
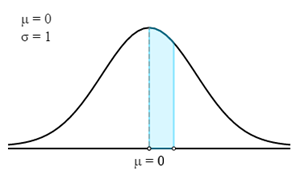
Om de Z-Score te vinden, moeten we eigenlijk de waarschijnlijkheid in het gemarkeerde gebied vinden.
Dit wordt verkregen door 0,30 van 0,50 af te trekken. Daarom is de waarschijnlijkheid van het gemarkeerde gebied 0,20.
Nu moeten we in de Z-tabel de dichtstbijzijnde waarschijnlijkheid tot 0,20 vinden. De overeenkomstige Z-Score is 0,524.
Vervolgens moeten we de X-waarde vinden met behulp van de Z-Score-formule.
- Z = (X - μ)/σ
- 0,524 = (X - 55)/10
- X = (0,524 × 10) + 55
- X = 60,24
Daarom is de minimale slaagscore voor het examen 60,24.