Nie znaleziono wyników
Nie możemy teraz znaleźć niczego z tym terminem, spróbuj wyszukać coś innego.
Kalkulator Z-Score
Kalkulator Z-Score pomaga uzyskać z-score normalnego rozkładu, konwertować między z-score a prawdopodobieństwem, oraz określać prawdopodobieństwo pomiędzy 2 z-skorami.
| Wynik | ||
|---|---|---|
| Wynik Z | 1 | |
| Prawdopodobieństwo x<5 | 0.84134 | |
| Prawdopodobieństwo x>5 | 0.15866 | |
| Prawdopodobieństwo 3<x<5 | 0.34134 | |
| Wynik | ||
|---|---|---|
| Wynik Z | 2 | |
| P(x<Z) | 0.97725 | |
| P(x>Z) | 0.02275 | |
| P(0<x<Z) | 0.47725 | |
| P(-Z<x<Z) | 0.9545 | |
| P(x<-Z or x>Z) | 0.0455 | |
| Wynik | ||
|---|---|---|
| P(-1<x<0) | 0.34134 | |
| P(x<-1 or x>0) | 0.65866 | |
| P(x<-1) | 0.15866 | |
| P(x>0) | 0.5 | |
Wystąpił błąd w twoim obliczeniu.
Spis treści
- Co to jest z-score?
- Formuła Z-Score
- Interpretacja wyników uzyskanego Z-score
- Z-score i odchylenie standardowe
- Z-score a rozkład normalny
- Porównanie punktów danych
- Normalizacja danych
- Testowanie hipotez
- Skalowanie cech
- Modelowanie predykcyjne
- Korzystanie z tabeli Z-score
- Znalezienie prawdopodobieństwa z Z-score
- Znalezienie odpowiadających wartości dla określonego prawdopodobieństwa

Kalkulator Z-Score może być używany do wszelkiego rodzaju obliczeń związanych ze Z-Score. Możesz wprowadzić surowy wynik (X), średnią populacji (μ) oraz odchylenie standardowe (σ) w pierwszym kalkulatorze, aby znaleźć Z-Score wraz z krokami i prawdopodobieństwami związanymi z tym wynikiem.
Konwerter Z-Score i Prawdopodobieństwa pomaga konwertować między Z-Score a prawdopodobieństwami bez odwoływania się do tabeli Z. Wyniki będą zawierać wszystkie możliwe obliczenia prawdopodobieństwa z tym pojedynczym z-score. Użyj ostatniego kalkulatora, aby znaleźć prawdopodobieństwo między 2 Z-Score.
Co to jest z-score?
Z-score to miara statystyczna, która opisuje liczbę odchyleń standardowych punktu danych od średniej zbioru danych. Z-score jest używane do porównywania pojedynczego punktu danych z całym zbiorem danych i pomaga w standaryzacji danych, aby były łatwiejsze do porównania i analizy.
Z-score pozwala nam określić, jak "typowy" lub odwrotnie "nietypowy" jest pojedynczy punkt danych w porównaniu z całym zbiorem danych.
- Wykrywanie wartości odstających: Z-score może pomóc nam zidentyfikować punkty danych, które znacznie różnią się od reszty danych. Jest to użyteczne w obszarach takich jak finanse i badania medyczne, gdzie wartości odstające mogą wskazywać na ważne wzorce lub anomalie.
- Porównywanie danych z różnych zestawów: Z-score pozwala nam porównywać dane z różnych zestawów, nawet jeśli mają różne jednostki lub zakresy. Jest to użyteczne w obszarach takich jak uczenie maszynowe, gdzie potrzebne jest porównanie danych z różnych źródeł do budowania modeli.
- Normalizacja danych: Przekształcając dane w Z-scores, możemy standaryzować dane i ułatwić ich porównywanie i analizę. Jest to użyteczne w obszarach takich jak wizualizacja danych, gdzie musimy przedstawić dane w zrozumiały sposób.
Formuła Z-Score
Z-Score dla populacji
Z = Surowy wynik - Średnia populacji / Odchylenie standardowe populacji
Z = (X - μ) / σ
Z-Score dla próbki
Z = Surowy wynik - Średnia próbki / Odchylenie standardowe próbki
Z = (X - x̄) / s
Interpretacja wyników uzyskanego Z-score
Pozytywny Z-score: Pozytywny Z-score oznacza, że twój punkt danych jest powyżej średniej wartości zbioru danych. Innymi słowy, zaobserwowany punkt danych jest wyższy niż typowa wartość w zbiorze danych.
Negatywny Z-score: Negatywny Z-score oznacza, że twój punkt danych jest poniżej średniej wartości zbioru danych. Innymi słowy, zaobserwowany punkt danych jest niższy niż typowa wartość w zbiorze danych.
Z-score: Z-score informuje, jak daleko twój punkt danych jest od średniej zbioru danych. Im większy Z-score, tym dalej zaobserwowany punkt danych jest od średniej wartości.
Z-score i odchylenie standardowe
Z-score i odchylenie standardowe są ze sobą związane, ponieważ odchylenie standardowe jest używane do obliczenia Z-score. W rzeczywistości odchylenie standardowe jest kluczowym składnikiem formuły Z-score.
Odchylenie standardowe jest miarą rozproszenia zbioru danych. Pokazuje, jak daleko każdy punkt danych jest od średniej wartości zbioru danych. Im większe odchylenie standardowe, tym większe rozproszenie danych.
Z-score z kolei mówi, jak daleko jeden punkt danych jest od średniej zbioru danych w stosunku do odchylenia standardowego. Korzystając z odchylenia standardowego do obliczenia Z-score, można porównać jeden punkt danych z całym zbiorem danych i zobaczyć, jak jest on niezwykły lub typowy.
Z-score a rozkład normalny
Rozkład normalny to typ rozkładu, który często występuje w wielu zjawiskach rzeczywistego świata. Jest to krzywa dzwonowa, która reprezentuje rozkład danych wokół średniej zbioru danych. Rozkład normalny jest również znany jako rozkład Gaussa, od matematyka Carla Friedricha Gaussa.
Z-score to sposób mierzenia, jak daleko jeden punkt danych jest od średniej zbioru danych w stosunku do odchylenia standardowego. Przekształcając każdy punkt danych na Z-score, można porównać indywidualny punkt danych z całym zbiorem danych i zobaczyć, jak jest on niezwykły lub typowy.
Związek między Z-score a rozkładem normalnym polega na tym, że Z-score może być używane do standaryzacji danych i dostosowania ich do rozkładu normalnego. Oznacza to, że można przekształcić dowolny zbiór danych na rozkład normalny, przekształcając każdy punkt danych na Z-score. Jest to użyteczne, ponieważ wiele metod statystycznych zakłada, że dane są normalnie rozłożone, więc przekształcenie danych na rozkład normalny może pomóc w dokładniejszym używaniu tych metod.
Porównanie punktów danych
Z-score może pomóc zrozumieć, jak daleko jeden punkt danych jest od średniej zbioru danych w stosunku do odchylenia standardowego.
Nasz przykład użycia Z-score do porównania punktów danych dotyczy finansów. Na przykład zainwestowałeś w dwa różne portfele akcji i chcesz porównać ich wyniki. Średni zwrot z portfela A wynosi 10% przy odchyleniu standardowym 2%, a średni zwrot z portfela B wynosi 8% przy odchyleniu standardowym 3%. Przekształcając zwroty na Z-score, możesz porównać zwroty z każdego portfela i określić, który z nich radzi sobie lepiej.
Innym praktycznym przykładem użycia Z-score do porównania punktów danych jest sport. Na przykład chcesz porównać wyniki dwóch koszykarzy, gracza A i gracza B. Gracz A zdobywa średnio 20 punktów na mecz przy odchyleniu standardowym 5 punktów, a gracz B zdobywa średnio 18 punktów na mecz przy odchyleniu standardowym 3 punktów. Przekształcając wyniki na Z-score, możesz porównać wyniki każdego gracza i określić, który z nich radzi sobie lepiej.
Normalizacja danych
Normalizacja danych to proces przekształcania danych do standardowej skali, aby można je było łatwo porównywać i analizować. Jest to ważne, ponieważ dane mogą mieć różne kształty i skale, a normalizowanie danych zapewnia, że są one na tej samej skali, co ułatwia ich porównanie i analizę.
Przekształcając każdy punkt danych na Z-score, można standaryzować dane i umieścić je na tej samej skali. Dzieje się tak, ponieważ Z-score zawsze znajduje się na standardowej skali, gdzie średnia wynosi 0, a odchylenie standardowe 1.
Jednym z praktycznych przykładów użycia Z-score do normalizacji danych jest psychologia. Na przykład chcesz porównać wyniki dwóch testów IQ, Test A i Test B. Test A ma średni wynik 100 ze standardowym odchyleniem 15, a test B ma średni wynik 110 ze standardowym odchyleniem 10. Przekształcając wyniki na Z-score, można je ustandaryzować i sprowadzić do jednej skali, co ułatwia porównanie i analizę.
Innym praktycznym przykładem użycia Z-score do normalizacji danych jest edukacja. Na przykład chcesz porównać oceny dwóch uczniów, ucznia A i ucznia B. Uczeń A ma średnią ocenę 80 ze standardowym odchyleniem 5, a uczeń B ma średnią ocenę 90 ze standardowym odchyleniem 3. Przekształcając oceny na współczynniki Z, można ustandaryzować oceny i umieścić je na tej samej skali, co ułatwia porównanie i analizę.
Testowanie hipotez
Testowanie hipotez to technika statystyczna używana do określenia, czy istnieją wystarczające dowody na odrzucenie hipotezy zerowej, czyli standardowego założenia, że nie ma związku między dwiema zmiennymi. Jest to ważne w wielu dziedzinach, w tym w badaniach medycznych, naukach społecznych i biznesie, gdzie podejmowanie świadomych decyzji na podstawie danych jest kluczowe.
Podczas testowania hipotez, współczynniki Z mogą być używane do określenia prawdopodobieństwa wystąpienia określonego wyniku. Na przykład możesz testować, czy średnia waga grupy ludzi różni się od średniej wagi całej populacji. Możesz użyć Z-score, aby określić, czy różnica jest statystycznie znacząca.
Jednym z praktycznych przykładów użycia Z-score do testowania hipotez jest medycyna. Na przykład chcesz przetestować, czy nowy lek jest skuteczny w zmniejszaniu objawów określonej choroby. Możesz użyć Z-score, aby określić, czy różnica w objawach między grupą przyjmującą lek a grupą kontrolną jest statystycznie znacząca.
Innym praktycznym przykładem użycia Z-score do testowania hipotez jest finanse. Na przykład chcesz przetestować, czy dany zapas ma wyższy zwrot niż średni zapas na rynku. Możesz użyć Z-score, aby określić, czy różnica w zwrotach jest statystycznie znacząca.
Skalowanie cech
Skalowanie cech to technika używana w uczeniu maszynowym i innych aplikacjach analizy danych, aby zapewnić, że wszystkie cechy w zbiorze danych mają tę samą skalę. Jest to ważne, ponieważ niektóre algorytmy uczenia maszynowego są wrażliwe na skalę danych i mogą dawać niedokładne wyniki, jeśli skala nie jest dopasowana.
Jedną z powszechnych metod skalowania cech jest normalizacja Z-score, znana również jako standaryzacja. W tym procesie każda cecha jest przekształcana tak, aby jej średnia wartość wynosiła 0, a odchylenie standardowe 1. Formuła do obliczania Z-score cechy jest następująca:
Z = (X - Średnia) / Odchylenie standardowe
gdzie X to wartość cechy, Średnia to średnia tej cechy, a Odchylenie standardowe to odchylenie standardowe tej cechy.
Jednym z praktycznych przykładów użycia Z-score do skalowania cech jest wizja komputerowa. Przy pracy z danymi obrazowymi zwykle wymagane jest skalowanie wartości pikseli tak, aby mieściły się w zakresie od 0 do 1. Można to osiągnąć poprzez normalizację Z-score, ponieważ każda wartość piksela może być przekształcona tak, aby jej średnia wartość wynosiła 0, a odchylenie standardowe 1.
Innym praktycznym przykładem użycia Z-score do skalowania cech jest przetwarzanie języka naturalnego. Przy pracy z danymi tekstowymi powszechną praktyką jest skalowanie częstotliwości terminów i odwrotnej częstotliwości dokumentów (TF-IDF) tak, aby mieściły się w zakresie od 0 do 1. Można to również osiągnąć poprzez normalizację Z-score.
Modelowanie predykcyjne
Modelowanie predykcyjne to technika używana w uczeniu maszynowym i innych aplikacjach analizy danych do dokonywania prognoz na podstawie danych historycznych. Polega na trenowaniu modelu na zestawie danych i używaniu tego modelu do dokonywania prognoz na nowych, nieobserwowanych dotąd danych.
Jednym ważnym aspektem modelowania predykcyjnego jest selekcja cech, która polega na wybieraniu najbardziej istotnych cech z zestawu danych do użycia w modelu. Często preferowane są cechy, które są silnie skorelowane ze zmienną docelową, ponieważ mają one większe prawdopodobieństwo przewidzenia tej zmiennej.
Z-score może być używane do identyfikacji cech, które są silnie skorelowane ze zmienną docelową, ponieważ cechy o wysokim Z-score są bardziej prawdopodobne do przewidzenia zmiennej docelowej. Formuła do obliczania Z-score cechy jest następująca:
Z = (X - Średnia) / Odchylenie standardowe
gdzie X to wartość cechy, Średnia to średnia tej cechy, a Odchylenie standardowe to odchylenie standardowe tej cechy.
Praktycznym przykładem użycia Z-score w modelowaniu prognostycznym jest dziedzina finansów. Przy prognozowaniu cen akcji Z-score dotychczasowej wydajności akcji może być używane do określenia jej potencjalnego przyszłego zwrotu. Wysoki Z-score wskazuje, że przeszły zwrot z akcji jest znacznie powyżej średniej i może być projektowany na wyższe zwroty w przyszłości.
Innym praktycznym przykładem użycia Z-score w modelowaniu predykcyjnym jest dziedzina opieki zdrowotnej. Przy prognozowaniu wyników pacjentów, Z-score może być używane do określenia potencjalnych przyszłych wyników pacjenta. Wysoki Z-score wskazuje, że wyniki zdrowotne pacjenta są znacznie gorsze niż średnia i mogą wskazywać na złe przyszłe wyniki.
Korzystanie z tabeli Z-score
Tabela Z, znana również jako standardowa tabela normalna lub jednostkowa tabela normalna, to tabela zawierająca znormalizowane wartości używane do obliczania prawdopodobieństwa, że dana statystyka znajdzie się poniżej, powyżej lub pomiędzy standardowym rozkładem normalnym.
| z | 0 | 0,01 | 0,02 | 0,03 | 0,04 | 0,05 | 0,06 | 0,07 | 0,08 | 0,09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0,00399 | 0,00798 | 0,01197 | 0,01595 | 0,01994 | 0,02392 | 0,0279 | 0,03188 | 0,03586 |
| 0,1 | 0,03983 | 0,0438 | 0,04776 | 0,05172 | 0,05567 | 0,05962 | 0,06356 | 0,06749 | 0,07142 | 0,07535 |
| 0,2 | 0,07926 | 0,08317 | 0,08706 | 0,09095 | 0,09483 | 0,09871 | 0,10257 | 0,10642 | 0,11026 | 0,11409 |
| 0,3 | 0,11791 | 0,12172 | 0,12552 | 0,1293 | 0,13307 | 0,13683 | 0,14058 | 0,14431 | 0,14803 | 0,15173 |
| 0,4 | 0,15542 | 0,1591 | 0,16276 | 0,1664 | 0,17003 | 0,17364 | 0,17724 | 0,18082 | 0,18439 | 0,18793 |
| 0,5 | 0,19146 | 0,19497 | 0,19847 | 0,20194 | 0,2054 | 0,20884 | 0,21226 | 0,21566 | 0,21904 | 0,2224 |
| 0,6 | 0,22575 | 0,22907 | 0,23237 | 0,23565 | 0,23891 | 0,24215 | 0,24537 | 0,24857 | 0,25175 | 0,2549 |
| 0,7 | 0,25804 | 0,26115 | 0,26424 | 0,2673 | 0,27035 | 0,27337 | 0,27637 | 0,27935 | 0,2823 | 0,28524 |
| 0,8 | 0,28814 | 0,29103 | 0,29389 | 0,29673 | 0,29955 | 0,30234 | 0,30511 | 0,30785 | 0,31057 | 0,31327 |
| 0,9 | 0,31594 | 0,31859 | 0,32121 | 0,32381 | 0,32639 | 0,32894 | 0,33147 | 0,33398 | 0,33646 | 0,33891 |
| 1 | 0,34134 | 0,34375 | 0,34614 | 0,34849 | 0,35083 | 0,35314 | 0,35543 | 0,35769 | 0,35993 | 0,36214 |
| 1,1 | 0,36433 | 0,3665 | 0,36864 | 0,37076 | 0,37286 | 0,37493 | 0,37698 | 0,379 | 0,381 | 0,38298 |
| 1,2 | 0,38493 | 0,38686 | 0,38877 | 0,39065 | 0,39251 | 0,39435 | 0,39617 | 0,39796 | 0,39973 | 0,40147 |
| 1,3 | 0,4032 | 0,4049 | 0,40658 | 0,40824 | 0,40988 | 0,41149 | 0,41308 | 0,41466 | 0,41621 | 0,41774 |
| 1,4 | 0,41924 | 0,42073 | 0,4222 | 0,42364 | 0,42507 | 0,42647 | 0,42785 | 0,42922 | 0,43056 | 0,43189 |
| 1,5 | 0,43319 | 0,43448 | 0,43574 | 0,43699 | 0,43822 | 0,43943 | 0,44062 | 0,44179 | 0,44295 | 0,44408 |
| 1,6 | 0,4452 | 0,4463 | 0,44738 | 0,44845 | 0,4495 | 0,45053 | 0,45154 | 0,45254 | 0,45352 | 0,45449 |
| 1,7 | 0,45543 | 0,45637 | 0,45728 | 0,45818 | 0,45907 | 0,45994 | 0,4608 | 0,46164 | 0,46246 | 0,46327 |
| 1,8 | 0,46407 | 0,46485 | 0,46562 | 0,46638 | 0,46712 | 0,46784 | 0,46856 | 0,46926 | 0,46995 | 0,47062 |
| 1,9 | 0,47128 | 0,47193 | 0,47257 | 0,4732 | 0,47381 | 0,47441 | 0,475 | 0,47558 | 0,47615 | 0,4767 |
| 2 | 0,47725 | 0,47778 | 0,47831 | 0,47882 | 0,47932 | 0,47982 | 0,4803 | 0,48077 | 0,48124 | 0,48169 |
| 2,1 | 0,48214 | 0,48257 | 0,483 | 0,48341 | 0,48382 | 0,48422 | 0,48461 | 0,485 | 0,48537 | 0,48574 |
| 2,2 | 0,4861 | 0,48645 | 0,48679 | 0,48713 | 0,48745 | 0,48778 | 0,48809 | 0,4884 | 0,4887 | 0,48899 |
| 2,3 | 0,48928 | 0,48956 | 0,48983 | 0,4901 | 0,49036 | 0,49061 | 0,49086 | 0,49111 | 0,49134 | 0,49158 |
| 2,4 | 0,4918 | 0,49202 | 0,49224 | 0,49245 | 0,49266 | 0,49286 | 0,49305 | 0,49324 | 0,49343 | 0,49361 |
| 2,5 | 0,49379 | 0,49396 | 0,49413 | 0,4943 | 0,49446 | 0,49461 | 0,49477 | 0,49492 | 0,49506 | 0,4952 |
| 2,6 | 0,49534 | 0,49547 | 0,4956 | 0,49573 | 0,49585 | 0,49598 | 0,49609 | 0,49621 | 0,49632 | 0,49643 |
| 2,7 | 0,49653 | 0,49664 | 0,49674 | 0,49683 | 0,49693 | 0,49702 | 0,49711 | 0,4972 | 0,49728 | 0,49736 |
| 2,8 | 0,49744 | 0,49752 | 0,4976 | 0,49767 | 0,49774 | 0,49781 | 0,49788 | 0,49795 | 0,49801 | 0,49807 |
| 2,9 | 0,49813 | 0,49819 | 0,49825 | 0,49831 | 0,49836 | 0,49841 | 0,49846 | 0,49851 | 0,49856 | 0,49861 |
| 3 | 0,49865 | 0,49869 | 0,49874 | 0,49878 | 0,49882 | 0,49886 | 0,49889 | 0,49893 | 0,49896 | 0,499 |
| 3,1 | 0,49903 | 0,49906 | 0,4991 | 0,49913 | 0,49916 | 0,49918 | 0,49921 | 0,49924 | 0,49926 | 0,49929 |
| 3,2 | 0,49931 | 0,49934 | 0,49936 | 0,49938 | 0,4994 | 0,49942 | 0,49944 | 0,49946 | 0,49948 | 0,4995 |
| 3,3 | 0,49952 | 0,49953 | 0,49955 | 0,49957 | 0,49958 | 0,4996 | 0,49961 | 0,49962 | 0,49964 | 0,49965 |
| 3,4 | 0,49966 | 0,49968 | 0,49969 | 0,4997 | 0,49971 | 0,49972 | 0,49973 | 0,49974 | 0,49975 | 0,49976 |
| 3,5 | 0,49977 | 0,49978 | 0,49978 | 0,49979 | 0,4998 | 0,49981 | 0,49981 | 0,49982 | 0,49983 | 0,49983 |
| 3,6 | 0,49984 | 0,49985 | 0,49985 | 0,49986 | 0,49986 | 0,49987 | 0,49987 | 0,49988 | 0,49988 | 0,49989 |
| 3,7 | 0,49989 | 0,4999 | 0,4999 | 0,4999 | 0,49991 | 0,49991 | 0,49992 | 0,49992 | 0,49992 | 0,49992 |
| 3,8 | 0,49993 | 0,49993 | 0,49993 | 0,49994 | 0,49994 | 0,49994 | 0,49994 | 0,49995 | 0,49995 | 0,49995 |
| 3,9 | 0,49995 | 0,49995 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49997 | 0,49997 |
| 4 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49998 | 0,49998 | 0,49998 | 0,49998 |
Aby użyć tabeli Z-score, musisz znaleźć wiersz odpowiadający twojemu obliczonemu Z-score, a następnie zlokalizować odpowiadającą mu kolumnę, która podaje obszar (prawdopodobieństwo) pod standardową krzywą normalną. Uzyskana wartość jest przybliżonym prawdopodobieństwem, że zmienna losowa z normalnego rozkładu standardowego będzie mniejsza lub równa twojemu obliczonemu Z-score.
Na przykład, jeśli masz Z-score równy 1,96, szukasz w tabeli Z wiersza odpowiadającego 1,9 i kolumny odpowiadającej 0,06. Uzyskana wartość podaje obszar pod standardową krzywą normalną po prawej stronie 1,96. Ta wartość wynosi około 0,975, co oznacza, że około 97,5% danych z normalnego rozkładu standardowego będzie mniejsze lub równe 1,96.
Ważne jest zauważenie, że tabela Z-score działa tylko dla normalnego rozkładu standardowego ze średnią równą 0 i odchyleniem standardowym równym 1. Jeśli twoje dane nie odpowiadają temu rozkładowi, musisz je najpierw ustandaryzować, przekształcając dane na Z-score.
Znalezienie prawdopodobieństwa z Z-score
Gdy przekształcimy zmienną rozłożoną normalnie na Z-score, możemy użyć tabeli Z-score i znaleźć proporcję obszaru pod krzywą normalną. Całkowity obszar pod standardową krzywą normalną jest równy 1. Dlatego proporcja obszaru pokrytego w krzywej normalnej jest równa prawdopodobieństwu tego Z-score.
Przykład 1
Wagi zawodników boksu są normalnie rozłożone ze średnią wynoszącą 75 kg i odchyleniem standardowym 3 kg. Jakie jest prawdopodobieństwo, że waga losowo wybranego zawodnika wynosi;
- a) Więcej niż 78 kg?
- b) Mniej niż 69 kg?
- c) Więcej niż 72 kg?
- d) Mniej niż 79,5 kg?
- e) Pomiędzy 72 kg a 76,5 kg?
- f) Pomiędzy 72 kg a 73,5 kg?
a) Jakie jest prawdopodobieństwo, że losowo wybrany zawodnik waży więcej niż 78 kg?
- X > 78
- μ = 75
- σ = 3
$$P(X>78)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{78-75}{3}\right)=P(Z>1)$$
Najpierw narysujemy to na krzywej Z.
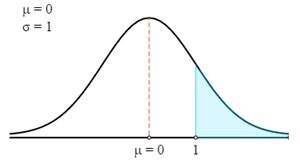
Teraz użyjemy tabeli Z-score, aby znaleźć odpowiednie prawdopodobieństwo dla obliczonego Z-score.
Pamiętaj, że Z-score zawsze daje prawdopodobieństwo między Z-score a średnią. Aby uzyskać prawdopodobieństwo wyróżnionego obszaru na wykresie, musimy odjąć to prawdopodobieństwo od 0,5. (Całkowite prawdopodobieństwo pod krzywą wynosi 1, a średnia standardowego rozkładu równomiernie dzieli na 2 części. Stąd prawdopodobieństwo od punktu średniej do każdego końca wynosi 0,5.)
- P (X > 78) = P (Z > 1)
- P (X > 78) = 0,5 - P(0 < Z < 1)
- P (X > 78) = 0,5 - 0,3413
- P (X > 78) = 0,1587
Zatem istnieje prawdopodobieństwo 0,1587, że waga losowo wybranego zawodnika wynosi więcej niż 78 kg.
b) Jakie jest prawdopodobieństwo, że losowo wybrany zawodnik waży mniej niż 69 kg?
- X < 69
- μ = 75
- σ = 3
$$P(X<69)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{69-75}{3}\right)=P(Z<-2)$$
Najpierw narysujemy to na krzywej Z.
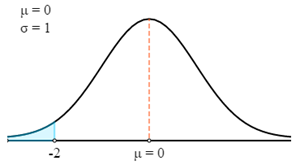
Teraz użyjemy tabeli Z-score, aby znaleźć odpowiednie prawdopodobieństwo dla obliczonego Z-score.
Pamiętaj, że Z-score zawsze daje prawdopodobieństwo między Z-score a średnią. Aby uzyskać prawdopodobieństwo wyróżnionego obszaru na wykresie, musimy odjąć to prawdopodobieństwo od 0,5.
- P (X < 69) = P (Z < -2)
- P (X < 69) = 0,5 - P (0 > Z > -2)
- P (X < 69) = 0,5 - 0,4772
- P (X < 69) = 0,0228
Zatem istnieje prawdopodobieństwo 0,0228, że waga losowo wybranego zawodnika wynosi mniej niż 69 kg.
c) Jakie jest prawdopodobieństwo, że waga losowo wybranego zawodnika mieści się między 72 kg a 76,5 kg?
- 72 < X < 76,5
- μ = 75
- σ = 3
$$P(72 \lt X \lt 76,5)=P\left(\frac{X-μ}{σ} \lt Z \lt \frac{X-μ}{σ}\right)=P\left(\frac{72-75}{3} \lt Z \lt \frac{76,5-75}{3}\right)=P(-1 \lt Z \lt 0,5)$$
Najpierw narysujemy to na krzywej Z.
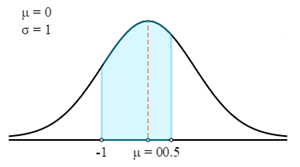
Teraz użyjemy tabeli Z-score, aby znaleźć odpowiednie prawdopodobieństwo dla obliczonego Z-score.
Pamiętaj, że Z-score zawsze daje prawdopodobieństwo między Z-score a średnią. Aby uzyskać prawdopodobieństwo wyróżnionego obszaru na wykresie, możesz dodać razem prawdopodobieństwa 2 Z-score.
- P (72 < X < 76,5) = P (-1 < Z < 0,5)
- P (72 < X < 76,5) = 0,3413 + 0,1915
- P (72 < X < 76,5) = 0,5328
Zatem istnieje prawdopodobieństwo 0,5328, że waga losowo wybranego zawodnika mieści się między 72 kg a 76,5 kg.
W tym przypadku musisz użyć kalkulatora prawdopodobieństwa między dwoma Z-score, aby szybko znaleźć odpowiedź.
Znalezienie odpowiadających wartości dla określonego prawdopodobieństwa
Gdy wiemy, że rozkład jest normalny, możemy znaleźć odpowiadające wartości dla określonych prawdopodobieństw na podstawie Z-Score.
Przykład 2
Oceny kandydatów na egzaminie konkursowym są przybliżenie normalnie rozłożone, ze średnią 55 i odchyleniem standardowym 10. Jeśli najlepsze 30% kandydatów zda egzamin, znajdź minimalną ocenę zaliczającą.
Rozwiązanie
W tym przypadku musimy najpierw znaleźć odpowiadający Z-score dla danego prawdopodobieństwa lub procentu.
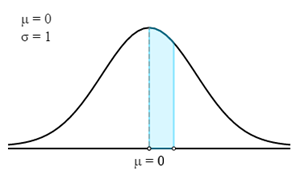
Aby znaleźć Z-Score, musimy faktycznie znaleźć prawdopodobieństwo w wyróżnionym obszarze.
Otrzymuje się je poprzez odjęcie 0,30 od 0,50. Dlatego prawdopodobieństwo wyróżnionego obszaru wynosi 0,20.
Teraz w tabeli Z-score musimy znaleźć prawdopodobieństwo najbliższe 0,20. Odpowiadający Z-Score to 0,524.
Następnie musimy znaleźć wartość X, używając formuły Z-Score.
- Z = (X - μ)/σ
- 0,524 = (X - 55)/10
- X = (0,524 × 10) + 55
- X = 60,24
Zatem minimalna zdawalna ocena na egzaminie to 60,24.