Không tìm thấy kết quả nào
Chúng tôi không thể tìm thấy bất cứ điều gì với thuật ngữ đó vào lúc này, hãy thử tìm kiếm cái gì đó khác.
Máy tính điểm Z (Z-Score)
Máy tính điểm Z giúp xác định điểm z của phân phối chuẩn, chuyển đổi giữa điểm z và xác suất, và lấy xác suất giữa 2 điểm z.
| Kết quả | ||
|---|---|---|
| Điểm Z | 1 | |
| Xác suất của x<5 | 0.84134 | |
| Xác suất của x>5 | 0.15866 | |
| Xác suất của 3<x<5 | 0.34134 | |
| Kết quả | ||
|---|---|---|
| Điểm Z | 2 | |
| P(x<Z) | 0.97725 | |
| P(x>Z) | 0.02275 | |
| P(0<x<Z) | 0.47725 | |
| P(-Z<x<Z) | 0.9545 | |
| P(x<-Z or x>Z) | 0.0455 | |
| Kết quả | ||
|---|---|---|
| P(-1<x<0) | 0.34134 | |
| P(x<-1 or x>0) | 0.65866 | |
| P(x<-1) | 0.15866 | |
| P(x>0) | 0.5 | |
Có lỗi với phép tính của bạn.
Mục lục
- Điểm z (z-score) là gì?
- Công thức điểm Z (Z-Score)
- Giải thích kết quả của điểm Z thu được
- Điểm Z và độ lệch chuẩn
- Điểm Z và phân phối chuẩn
- So sánh các điểm dữ liệu
- Chuẩn hóa dữ liệu
- Kiểm tra giả thuyết
- Chỉnh sửa tỷ lệ đặc trưng
- Mô hình dự đoán
- Sử dụng bảng Z-score
- Tìm xác suất từ điểm Z
- Tìm các giá trị tương ứng cho xác suất được chỉ định

Máy tính điểm Z có thể được sử dụng cho bất kỳ loại phép tính nào liên quan đến điểm Z-Score. Bạn có thể nhập một điểm số thô (X), giá trị trung bình của tổng thể (μ), và độ lệch chuẩn (σ) vào máy tính này để tìm điểm Z (Z-Score) với các bước và xác suất liên quan đến điểm số đó.
Trình chuyển đổi giữa điểm Z (Z-score) và Xác suất giúp bạn chuyển đổi giữa Z-Scores và xác suất mà không cần tham chiếu đến bảng Z. Kết quả sẽ bao gồm tất cả các phép tính toán xác suất có thể có với một giá trị Z-score duy nhất.
Sử dụng công cụ máy tính cuối cùng để tìm xác suất giữa 2 điểm Z-Scores.
Điểm z (z-score) là gì?
Điểm Z (Z-score) là một đại lượng thống kê mô tả số lượng độ lệch chuẩn của một điểm dữ liệu so với giá trị trung bình của một tập dữ liệu. Z-score được sử dụng để so sánh một điểm dữ liệu duy nhất với toàn bộ tập dữ liệu và giúp chuẩn hóa dữ liệu để dễ dàng so sánh và phân tích hơn.
Z-score cho phép chúng ta xác định mức "bình thường" hoặc "không bình thường" của một điểm dữ liệu so với toàn bộ tập dữ liệu.
- Phát hiện các điểm outlier (quá lớn hoặc quá nhỏ): Z-score có thể giúp chúng ta xác định các điểm dữ liệu khác biệt đáng kể so với phần còn lại của dữ liệu. Điều này rất hữu ích trong các lĩnh vực như tài chính và nghiên cứu y học, nơi các điểm outlier có thể chỉ ra các mẫu quan trọng hoặc bất thường.
- So sánh dữ liệu từ các tập dữ liệu khác nhau: Z-score cho phép chúng ta so sánh dữ liệu từ các tập dữ liệu khác nhau, ngay cả khi chúng có các đơn vị hoặc phạm vi khác nhau. Điều này hữu ích trong các lĩnh vực như học máy (machine learning), nơi bạn cần so sánh dữ liệu từ các nguồn khác nhau để xây dựng mô hình.
- Chuẩn hóa dữ liệu: Bằng cách chuyển đổi dữ liệu thành Z-score, chúng ta có thể chuẩn hóa dữ liệu và làm cho nó dễ dàng hơn trong việc so sánh và phân tích. Điều này hữu ích trong các lĩnh vực như trực quan hóa dữ liệu, khi chúng ta cần trình bày dữ liệu một cách dễ hiểu.
Công thức điểm Z (Z-Score)
Điểm Z cho tổng thể
Z = Điểm thô - Giá trị trung bình tổng thể / Độ lệch chuẩn tổng thể
Z = (X - μ) / σ
Điểm Z cho một mẫu
Z = Điểm thô - Giá trị trung bình của mẫu / Độ lệch chuẩn mẫu
Z = (X - x̄) / s
Giải thích kết quả của điểm Z thu được
Điểm Z dương: Điểm Z dương có nghĩa là điểm dữ liệu của bạn cao hơn giá trị trung bình của tập dữ liệu. Nói cách khác, điểm dữ liệu được quan sát của bạn cao hơn giá trị điển hình trong tập dữ liệu.
Điểm Z âm: Điểm Z âm có nghĩa là điểm dữ liệu của bạn thấp hơn giá trị trung bình của tập dữ liệu. Nói cách khác, điểm dữ liệu được quan sát của bạn thấp hơn giá trị điển hình trong tập dữ liệu.
Điểm Z: Điểm Z cho bạn biết điểm dữ liệu của bạn cách điểm trung bình của tập dữ liệu là bao nhiêu. Điểm Z càng lớn thì điểm dữ liệu quan sát của bạn càng cách xa giá trị trung bình.
Điểm Z và độ lệch chuẩn
Điểm Z và độ lệch chuẩn có liên quan với nhau vì độ lệch chuẩn được sử dụng để tính điểm Z. Trên thực tế, độ lệch chuẩn là thành phần chính trong công thức tính điểm Z.
Độ lệch chuẩn là thước đo mức độ phân tán của tập dữ liệu. Nó cho thấy mỗi điểm dữ liệu cách bao xa so với giá trị trung bình của tập dữ liệu. Độ lệch chuẩn càng lớn thì độ phân tán của dữ liệu càng lớn.
Bên cạnh đó, điểm Z cho bạn biết khoảng cách giữa một điểm dữ liệu với giá trị trung bình của tập dữ liệu trong tương quan với độ lệch chuẩn. Bằng cách sử dụng độ lệch chuẩn để tính điểm Z, bạn có thể so sánh một điểm dữ liệu với toàn bộ tập dữ liệu và xem mức độ bất thường hoặc mức độ điển hình của nó.
Điểm Z và phân phối chuẩn
Phân phối chuẩn là một loại phân phối thường thấy trong nhiều hiện tượng thực tế. Đó là một đường cong hình chuông biểu thị sự phân bố dữ liệu xung quanh giá trị trung bình của một tập hợp dữ liệu. Phân phối chuẩn còn được gọi là phân phối Gaussian, theo tên nhà toán học Carl Friedrich Gauss.
Điểm Z (Z-Score) là một cách đo khoảng cách giữa một điểm dữ liệu so với giá trị trung bình của tập dữ liệu trong tương quan với độ lệch chuẩn. Bằng cách chuyển đổi từng điểm dữ liệu thành điểm Z, bạn có thể so sánh một điểm dữ liệu riêng lẻ với toàn bộ tập dữ liệu và xem mức độ bất thường hoặc điển hình của nó.
Mối liên hệ giữa điểm Z và phân phối chuẩn là điểm Z có thể được sử dụng để chuẩn hóa dữ liệu và làm cho nó phù hợp với phân phối chuẩn. Điều này có nghĩa là bạn có thể chuyển đổi bất kỳ tập dữ liệu nào thành phân phối chuẩn bằng cách chuyển đổi từng điểm dữ liệu thành điểm Z. Điều này rất hữu ích vì nhiều phương pháp thống kê giả định rằng dữ liệu được phân phối chuẩn, do đó việc chuyển đổi dữ liệu sang phân phối chuẩn có thể giúp bạn sử dụng các phương pháp này chính xác và thuận tiện hơn.
So sánh các điểm dữ liệu
Z-score có thể giúp bạn biết được mức chênh lệch của một điểm dữ liệu nào đó so với giá trị trung bình của một tập dữ liệu trong mối tương quan với độ lệch chuẩn.
Ví dụ của chúng ta về việc sử dụng Z-score để so sánh các điểm dữ liệu áp dụng cho lĩnh vực tài chính. Ví dụ, bạn đã đầu tư vào hai danh mục cổ phiếu khác nhau và muốn so sánh hiệu suất của chúng. Hiệu suất trung bình của danh mục A là 10% với độ lệch chuẩn là 2%, và hiệu suất trung bình của danh mục B là 8% với độ lệch chuẩn là 3%. Bằng cách chuyển đổi hiệu suất thành Z-scores, bạn có thể so sánh hiệu suất của mỗi danh mục và xác định xem danh mục nào có hiệu suất tốt hơn.
Một ví dụ thực tế khác về việc sử dụng Z-score để so sánh các điểm dữ liệu là trong thể thao. Ví dụ, bạn muốn so sánh hiệu suất của hai cầu thủ bóng rổ, cầu thủ A và cầu thủ B. Cầu thủ A ghi trung bình 20 điểm mỗi trận đấu với độ lệch chuẩn là 5 điểm, và cầu thủ B ghi trung bình 18 điểm mỗi trận đấu với độ lệch chuẩn là 3 điểm. Bằng cách chuyển đổi các điểm số thành Z-score, bạn có thể so sánh hiệu suất của mỗi cầu thủ và xác định xem cầu thủ nào thi đấu tốt hơn.
Chuẩn hóa dữ liệu
Chuẩn hóa dữ liệu là quá trình chuyển đổi dữ liệu về một tỷ lệ chuẩn để dễ dàng so sánh và phân tích. Điều này là quan trọng vì dữ liệu có thể có các dạng và tỷ lệ khác nhau, và việc chuẩn hóa dữ liệu giúp đảm bảo rằng chúng ở trên cùng một tỷ lệ và làm cho việc so sánh và phân tích trở nên dễ dàng hơn.
Bằng cách chuyển đổi mỗi điểm dữ liệu thành một điểm Z, bạn có thể chuẩn hóa dữ liệu và đưa nó về cùng một tỷ lệ. Có được điều đó là bởi vì Z-score luôn ở trên một tỷ lệ chuẩn, trong đó trung bình là 0 và độ lệch chuẩn là 1.
Một ví dụ thực tế về việc sử dụng Z-score để chuẩn hóa dữ liệu liên quan đến lĩnh vực tâm lý học. Ví dụ, bạn muốn so sánh kết quả của hai bài kiểm tra IQ, Kiểm tra A và Kiểm tra B. Kiểm tra A có điểm trung bình là 100 với độ lệch chuẩn là 15, và kiểm tra B có điểm trung bình là 110 với độ lệch chuẩn là 10. Bằng cách chuyển đổi các điểm thành Z-score, các điểm có thể được chuẩn hóa và đưa về cùng một tỷ lệ đơn, điều này giúp thuận tiện cho việc so sánh và phân tích.
Một ví dụ thực tế khác về việc sử dụng Z-score để chuẩn hóa dữ liệu là trong lĩnh vực giáo dục. Ví dụ, bạn muốn so sánh điểm của hai học sinh, học sinh A và học sinh B. Học sinh A có điểm trung bình là 80 với độ lệch chuẩn là 5, và học sinh B có điểm trung bình là 90 với độ lệch chuẩn là 3. Bằng cách chuyển đổi các điểm số thành Z-score, bạn có thể chuẩn hóa các điểm số và đưa chúng về cùng một tỷ lệ, điều này làm cho việc so sánh và phân tích trở nên dễ dàng hơn.
Kiểm tra giả thuyết
Kiểm định giả thuyết là một kỹ thuật thống kê được sử dụng để xác định liệu có đủ dẫn chứng để chấp nhận giả thuyết đó hay không. Giả thuyết tiêu chuẩn là không có mối liên hệ nào giữa hai biến. Điều này quan trọng trong nhiều lĩnh vực, bao gồm nghiên cứu y học, khoa học xã hội và kinh doanh, khi việc ra quyết định dựa trên dữ liệu là quan trọng.
Khi kiểm định giả thuyết, Z-score có thể được sử dụng để xác định xác suất xảy ra của một kết quả cụ thể. Ví dụ, bạn có thể kiểm tra liệu trọng lượng trung bình của một nhóm người có khác biệt so với trọng lượng trung bình của toàn bộ dân số hay không. Bạn có thể sử dụng Z-score để xác định xem sự khác biệt có ý nghĩa thống kê hay không.
Một ví dụ thực tế về việc sử dụng Z-score để kiểm định giả thuyết là trong lĩnh vực y học. Ví dụ, bạn muốn kiểm tra liệu một loại phương thuốc mới có hiệu quả trong việc giảm các triệu chứng của một căn bệnh cụ thể hay không. Bạn có thể sử dụng Z-score để xác định xem sự khác biệt về triệu chứng giữa nhóm người sử dụng thuốc và nhóm người không sử dụng thuốc có lớn hay không.
Một ví dụ thực tế khác về việc sử dụng điểm Z để kiểm định giả thuyết là trong lĩnh vực tài chính. Ví dụ, bạn muốn kiểm tra liệu một cổ phiếu cụ thể có tỷ lệ lợi nhuận cao hơn so với cổ phiếu trung bình trên thị trường hay không. Bạn có thể sử dụng Z-score để xác định xem sự khác biệt về lợi nhuận có ý nghĩa thống kê hay không.
Chỉnh sửa tỷ lệ đặc trưng
Feature scaling (Chỉnh sửa tỉ lệ đặc trưng) là một kỹ thuật được sử dụng trong máy học (machine learning) và các ứng dụng phân tích dữ liệu khác nhằm đảm bảo rằng tất cả các đối tượng trong tập dữ liệu có cùng một tỷ lệ. Điều này là quan trọng vì một số thuật toán máy học nhạy cảm đối với tỷ lệ của dữ liệu và có thể cho kết quả không chính xác nếu tỷ lệ không phù hợp.
Một phương pháp phổ biến để chỉnh sửa tỷ lệ các đối tượng là chuẩn hóa điểm Z (Z-score), còn được biết đến với tên gọi là chuẩn hóa. Trong quá trình này, mỗi đối tượng được chuyển đổi sao cho giá trị trung bình của nó là 0 và độ lệch chuẩn là 1. Công thức tính Z-score của một đối tượng là như sau:
Z = (X - Giá trị trung bình) / Độ lệch chuẩn
trong đó X là giá trị của đối tượng, Giá trị trung bình là giá trị trung bình của đối tượng và Độ lệch chuẩn là Độ lệch chuẩn của đối tượng.
Một ví dụ thực tế về việc sử dụng điểm Z để chia tỷ lệ các đối tượng là trong lĩnh vực thị giác máy tính. Khi làm việc với dữ liệu hình ảnh, thường phải chia tỷ lệ các giá trị pixel sao cho chúng nằm trong phạm vi từ 0 đến 1. Điều này có thể đạt được bằng cách chuẩn hóa điểm Z, vì mỗi giá trị pixel có thể được chuyển đổi sao cho giá trị trung bình của nó là 0 và độ lệch chuẩn của nó là 1.
Một ví dụ thực tế khác về việc sử dụng điểm Z để chia tỷ lệ đối tượng là xử lý ngôn ngữ tự nhiên. Khi làm việc với dữ liệu văn bản, thông thường chia tỷ lệ các giá trị tần số thuật ngữ và tần số tài liệu nghịch đảo (TF-IDF) sao cho chúng nằm trong khoảng từ 0 đến 1. Điều này cũng có thể đạt được bằng cách sử dụng chuẩn hóa điểm Z.
Mô hình dự đoán
Mô hình dự đoán là một kỹ thuật được sử dụng trong máy học và các ứng dụng phân tích dữ liệu khác để dự đoán dựa trên dữ liệu lịch sử. Nó bao gồm việc huấn luyện một mô hình trên một tập dữ liệu và sử dụng mô hình đó để dự đoán trên tập dữ liệu mới, chưa được nhìn thấy trước đó.
Một khía cạnh quan trọng của mô hình dự đoán là việc chọn đặc điểm, bao gồm việc chọn ra những đặc điểm quan trọng nhất từ tập dữ liệu để sử dụng trong mô hình. Thường, các đặc điểm mà có mối tương quan cao với biến mục tiêu sẽ được ưu tiên vì chúng có khả năng dự đoán cao hơn cho biến mục tiêu.
Z-score có thể được sử dụng để xác định các đặc điểm có mối tương quan cao với biến mục tiêu vì các đặc điểm đó có Z-score cao hơn, sẽ có khả năng dự đoán cao hơn cho biến mục tiêu. Công thức tính Z-score của một đặc điểm là như sau:
Z = (X - Giá trị trung bình) / Độ lệch chuẩn
Trong đó, X là giá trị của đặc điểm, Trung bình là giá trị trung bình của đặc điểm, và Độ lệch chuẩn là Độ lệch chuẩn của đặc điểm.
Một ví dụ thực tế về việc sử dụng Z-score trong mô hình dự đoán thuộc lĩnh vực tài chính. Khi dự đoán giá cổ phiếu, Z-score về hiệu suất trước đó của cổ phiếu có thể được sử dụng để xác định tiềm năng lợi nhuận tương lai của nó. Một Z-score cao chỉ ra rằng hiệu suất trước đó của cổ phiếu cao hơn trung bình và có thể được dự đoán sẽ có lợi nhuận cao hơn trong tương lai.
Một ví dụ thực tế khác về việc sử dụng Z-score trong mô hình dự đoán là trong lĩnh vực chăm sóc sức khỏe. Khi dự đoán kết quả cho bệnh nhân, Z-score có thể được sử dụng để xác định tiềm năng của bệnh nhân cho kết quả tương lai. Một giá trị Z-score cao chỉ ra rằng kết quả sức khỏe của bệnh nhân xấu hơn đáng kể so với trung bình và có thể cho thấy kết quả tương lai không tốt.
Sử dụng bảng Z-score
Bảng Z-score, còn được gọi là bảng chuẩn hóa hoặc bảng phân phối chuẩn đơn vị, là một bảng chứa các giá trị đã được chuẩn hóa, và được sử dụng để tính xác suất của một thống kê cụ thể nằm dưới, trên hoặc giữa phân phối chuẩn đơn vị.
| z | 0 | 0,01 | 0,02 | 0,03 | 0,04 | 0,05 | 006 | 0,07 | 0,08 | 0,09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0,00399 | 0,00798 | 0,01197 | 0,01595 | 0,01994 | 0,02392 | 0,0279 | 0,03188 | 0,03586 |
| 0,1 | 0,03983 | 0,0438 | 0,04776 | 0,05172 | 0,05567 | 0,05962 | 0,06356 | 0,06749 | 0,07142 | 0,07535 |
| 0,2 | 0,07926 | 0,08317 | 0,08706 | 0,09095 | 0,09483 | 0,09871 | 0,10257 | 0,10642 | 0,11026 | 0,11409 |
| 0,3 | 0,11791 | 0,12172 | 0,12552 | 0,1293 | 0,13307 | 0,13683 | 0,14058 | 0,14431 | 0,14803 | 0,15173 |
| 0,4 | 0,15542 | 0,1591 | 0,16276 | 0,1664 | 0,17003 | 0,17364 | 0,17724 | 0,18082 | 018439 | 0,18793 |
| 0,5 | 0,19146 | 0,19497 | 0,19847 | 0,20194 | 0,2054 | 0,20884 | 0,21226 | 0,21566 | 0,21904 | 0,2224 |
| 0,6 | 0,22575 | 0,22907 | 0,23237 | 0,23565 | 0,23891 | 0,24215 | 0,24537 | 0,24857 | 0,25175 | 0,2549 |
| 0,7 | 0,25804 | 0,26115 | 0,26424 | 0,2673 | 0,27035 | 0,27337 | 0,27637 | 0,27935 | 0,2823 | 0,28524 |
| 0,8 | 0,28814 | 0,29103 | 0,29389 | 0,29673 | 0,29955 | 0,30234 | 0,30511 | 0,30785 | 0,31057 | 0,31327 |
| 0,9 | 0,31594 | 0,31859 | 0,32121 | 0,32381 | 0,32639 | 0,32894 | 0,33147 | 0,33398 | 0,33646 | 0,33891 |
| 1 | 0,34134 | 0,34375 | 0,34614 | 0,34849 | 0,35083 | 0,35314 | 0,35543 | 0,35769 | 0,35993 | 0,36214 |
| 1,1 | 0,36433 | 0,3665 | 0,36864 | 0,37076 | 0,37286 | 0,37493 | 0,37698 | 0,379 | 0,381 | 0,38298 |
| 1,2 | 0,38493 | 0,38686 | 0,38877 | 0,39065 | 0,39251 | 0,39435 | 0,39617 | 0,39796 | 0,39973 | 0,40147 |
| 1,3 | 0,4032 | 0,4049 | 0,40658 | 0,40824 | 0,40988 | 0,41149 | 0,41308 | 0,41466 | 0,41621 | 0,41774 |
| 1,4 | 0,41924 | 0,42073 | 0,4222 | 0,42364 | 0,42507 | 0,42647 | 0,42785 | 0,42922 | 0,43056 | 0,43189 |
| 1,5 | 0,43319 | 0,43448 | 0,43574 | 0,43699 | 0,43822 | 0,43943 | 0,44062 | 0,44179 | 0,44295 | 0,44408 |
| 1,6 | 0,4452 | 0,4463 | 0,44738 | 0,44845 | 0,4495 | 0,45053 | 0,45154 | 0,45254 | 0,45352 | 0,45449 |
| 1,7 | 0,45543 | 0,45637 | 0,45728 | 0,45818 | 0,45907 | 0,45994 | 0,4608 | 0,46164 | 0,46246 | 0,46327 |
| 1,8 | 0,46407 | 0,46485 | 0,46562 | 0,46638 | 0,46712 | 0,46784 | 0,46856 | 0,46926 | 0,46995 | 0,47062 |
| 1,9 | 0,47128 | 0,47193 | 0,47257 | 0,4732 | 0,47381 | 0,47441 | 0,475 | 0,47558 | 0,47615 | 0,4767 |
| 2 | 0,47725 | 0,47778 | 0,47831 | 0,47882 | 0,47932 | 0,47982 | 0,4803 | 0,48077 | 0,48124 | 0,48169 |
| 2,1 | 0,48214 | 0,48257 | 0,483 | 0,48341 | 0,48382 | 0,48422 | 0,48461 | 0,485 | 0,48537 | 0,48574 |
| 2,2 | 0,4861 | 0,48645 | 0,48679 | 0,48713 | 0,48745 | 0,48778 | 0,48809 | 0,4884 | 0,4887 | 0,48899 |
| 2,3 | 0,48928 | 0,48956 | 0,48983 | 0,4901 | 0,49036 | 0,49061 | 0,49086 | 0,49111 | 0,49134 | 0,49158 |
| 2,4 | 0,4918 | 0,49202 | 0,49224 | 0,49245 | 0,49266 | 0,49286 | 0,49305 | 0,49324 | 0,49343 | 0,49361 |
| 2,5 | 0,49379 | 0,49396 | 0,49413 | 0,4943 | 0,49446 | 0,49461 | 0,49477 | 0,49492 | 0,49506 | 0,4952 |
| 2,6 | 0,49534 | 0,49547 | 0,4956 | 0,49573 | 0.49585 | 0,49598 | 0,49609 | 0,49621 | 0,49632 | 0,49643 |
| 2,7 | 0,49653 | 0,49664 | 0,49674 | 0,49683 | 0,49693 | 0,49702 | 0,49711 | 0,4972 | 0,49728 | 0,49736 |
| 2,8 | 0,49744 | 0,49752 | 0,4976 | 0,49767 | 0,49774 | 0,49781 | 0,49788 | 0,49795 | 0,49801 | 0,49807 |
| 2,9 | 0,49813 | 0,49819 | 0,49825 | 0,49831 | 0,49836 | 0,49841 | 0,49846 | 0,49851 | 0,49856 | 0,49861 |
| 3 | 0,49865 | 0,49869 | 0,49874 | 0,49878 | 0,49882 | 0,49886 | 0,49889 | 0,49893 | 0,49896 | 0,499 |
| 3,1 | 0,49903 | 0,49906 | 0,4991 | 0,49913 | 0,49916 | 0,49918 | 0,49921 | 0,49924 | 0,49926 | 0,49929 |
| 3,2 | 0,49931 | 0,49934 | 0,49936 | 0,49938 | 0,4994 | 0,49942 | 0,49944 | 0,49946 | 0,49948 | 0,4995 |
| 3,3 | 0,49952 | 0,49953 | 0,49955 | 0,49957 | 0,49958 | 0,4996 | 0,49961 | 0,49962 | 0,49964 | 0,49965 |
| 3,4 | 0,49966 | 0,49968 | 0,49969 | 0,4997 | 0,49971 | 0,49972 | 0,49973 | 0,49974 | 0,49975 | 0,49976 |
| 3,5 | 0,49977 | 0,49978 | 0,49978 | 0,49979 | 0,4998 | 0,49981 | 0,49981 | 0,49982 | 0,49983 | 0,49983 |
| 3,6 | 0,49984 | 0,49985 | 0,49985 | 0,49986 | 0,49986 | 0,49987 | 0,49987 | 0,49988 | 0,49988 | 0,49989 |
| 3,7 | 0,49989 | 0,4999 | 0,4999 | 0,4999 | 0,49991 | 0,49991 | 0,49992 | 0,49992 | 0,49992 | 0,49992 |
| 3,8 | 0,49993 | 0,49993 | 0,49993 | 0,49994 | 0,49994 | 0,49994 | 0,49994 | 0,49995 | 0,49995 | 0,49995 |
| 3,9 | 0,49995 | 0,49995 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49996 | 0,49997 | 0,49997 |
| 4 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49997 | 0,49998 | 0,49998 | 0,49998 | 0,49998 |
Để sử dụng bảng z-score, bạn cần tìm hàng tương ứng với điểm z đã được tính toán và sau đó xác định cột tương ứng cung cấp cho bạn diện tích (xác suất) dưới đường cong chuẩn hóa tiêu chuẩn. Giá trị kết quả là xác suất gần đúng mà một biến ngẫu nhiên từ phân phối chuẩn chuẩn hóa sẽ nhỏ hơn hoặc bằng điểm z được tính toán của bạn.
Ví dụ: nếu bạn có điểm z là 1,96, bạn sẽ tìm trong bảng z-score hàng tương ứng với 1,9 và cột tương ứng với 0,06. Giá trị kết quả sẽ cung cấp cho bạn diện tích dưới đường cong chuẩn hóa tiêu chuẩn ở bên phải là 1,96. Giá trị này xấp xỉ 0,975, nghĩa là khoảng 97,5% dữ liệu từ phân phối chuẩn chuẩn sẽ nhỏ hơn hoặc bằng 1,96.
Điều quan trọng cần lưu ý là bảng z-score chỉ hoạt động đối với phân phối chuẩn chuẩn hóa có giá trị trung bình là 0 và độ lệch chuẩn là 1. Nếu dữ liệu của bạn không tuân theo phân phối này, trước tiên bạn cần phải chuẩn hóa nó bằng cách chuyển đổi dữ liệu thành các điểm z-score.
Tìm xác suất từ điểm Z
Khi chuyển đổi một biến có phân phối chuẩn thành điểm z, chúng ta có thể sử dụng bảng điểm Z và tìm tỷ lệ diện tích dưới đường cong chuẩn. Tổng diện tích dưới đường cong chuẩn thông thường bằng 1. Do đó, tỷ lệ diện tích được bao phủ trong đường chuẩn tiêu chuẩn bằng xác suất của điểm Z đó.
Ví dụ 1
Trọng lượng của các vận động viên quyền anh thường được phân phối với giá trị trung bình là 75 Kg và độ lệch chuẩn là 3 Kg. Xác suất để trọng lượng sau đây của một vận động viên được chọn ngẫu nhiên là bao nhiêu;
- a) Hơn 78 Kg?
- b) Dưới 69 kg?
- c) Trên 72 Kg?
- d) Dưới 79,5 kg?
- e) Từ 72 kg đến 76,5 kg?
- f) Từ 72 Kg đến 73,5 Kg?
a) Xác suất để một cầu thủ được chọn ngẫu nhiên nặng hơn 78 kg là bao nhiêu?
- X > 78
- μ = 75
- σ = 3
$$P(X>78)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{78-75}{3}\right)=P (Z>1)$$
Đầu tiên, chúng ta sẽ vẽ theo đường cong Z.
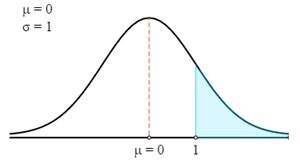
Bây giờ chúng ta sẽ sử dụng Bảng Z để tìm xác suất phù hợp cho Điểm Z được tính.
Hãy nhớ rằng Điểm Z luôn đưa ra xác suất nằm giữa điểm Z và giá trị trung bình. Để có được xác suất của vùng được đánh dấu trong biểu đồ, chúng ta cần giảm xác suất đó từ 0,5. (Tổng xác suất dưới đường cong là 1 và Giá trị trung bình của phân bố chuẩn được chia đều thành 2 phần. Do đó, xác suất từ Điểm trung bình đến một trong hai phía của điểm cuối là 0,5.)
- P (X > 78) = P (Z > 1)
- P (X > 78) = 0,5 - P(0 < Z < 1)
- P (X > 78) = 0,5 - 0,3413
- P (X > 78) = 0,1587
Do đó, một vận động viên được chọn ngẫu nhiên có trọng lượng lớn hơn 78 Kg có xác suất 0,1587.
b) Xác suất để một vận động viên được chọn ngẫu nhiên có cân nặng dưới 69 kg là bao nhiêu?
- X < 69
- μ = 75
- σ = 3
$$P(X<69)=P\left(Z>\frac{X-μ}{σ}\right)=P\left(Z>\frac{69-75}{3}\right)=P (Z<-2)$$
Đầu tiên, chúng ta sẽ vẽ theo đường cong Z.
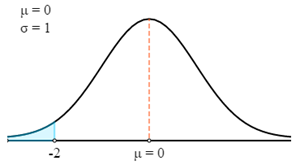
Bây giờ chúng ta sẽ sử dụng Bảng Z để tìm xác suất phù hợp cho Điểm Z được tính.
Hãy nhớ rằng Điểm Z luôn đưa ra xác suất nằm giữa điểm Z và giá trị trung bình. Để có được xác suất của vùng được đánh dấu trong biểu đồ, chúng ta cần giảm xác suất đó từ 0,5.
- P (X < 69) = P (Z < 69)
- P (X < 69) = 0,5 - P (0 > Z > -2)
- P (X < 69) = 0,5 - 0,4772
- P (X < 69) = 0,0228
Do đó, một vận động viên được chọn ngẫu nhiên có trọng lượng nhỏ hơn 69 Kg có xác suất 0,0228.
c) Xác suất để một cầu thủ được chọn ngẫu nhiên có cân nặng từ 72 kg đến 76,5 kg là bao nhiêu?
- 72 < X < 76,5
- μ = 75
- σ = 3
$$P(72 \lt X \lt 76,5)=P\left(\frac{X-μ}{σ} \lt Z \lt \frac{X-μ}{σ}\right)=P\left(\frac{72-75}{3} \lt Z \lt \frac{76,5-75}{3}\right)=P(-1 \lt Z \lt 0,5)$$
Đầu tiên, chúng ta sẽ vẽ theo đường cong Z.
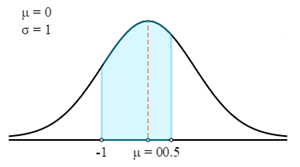
Bây giờ chúng ta sẽ sử dụng Bảng Z để tìm xác suất phù hợp cho Điểm Z được tính.
Hãy nhớ rằng Điểm Z luôn đưa ra xác suất nằm giữa điểm Z và giá trị trung bình. Để có được xác suất của vùng được đánh dấu trong biểu đồ, bạn có thể cộng xác suất của 2 điểm Z lại với nhau.
- P (72 < X < 76,5) = P (-1 < Z < 0,5)
- P (72 < X < 76,5) = 0,3413 + 0,1915
- P (72 < X < 76,5) = 0,5328
Do đó, một vận động viên được chọn ngẫu nhiên có cân nặng nằm trong khoảng từ 72 Kg đến 76,5 Kg có xác suất là 0,5328.
Trong trường hợp này, bạn phải sử dụng công cụ máy tính Xác suất giữa hai điểm Z để tìm ra câu trả lời một cách nhanh chóng.
Tìm các giá trị tương ứng cho xác suất được chỉ định
Khi chúng ta biết rằng phân phối đó là phân phối chuẩn, chúng ta có thể tìm thấy các giá trị tương ứng cho các xác suất được chỉ định dựa trên Điểm Z.
Ví dụ 2
Điểm số của các ứng viên trong một kỳ thi được phân phối gần như theo phân phối chuẩn, với giá trị trung bình là 55 và độ lệch chuẩn là 10. Nếu 30% ứng viên hàng đầu vượt qua kỳ thi, hãy tìm điểm đậu tối thiểu.
Lời giải
Trong trường hợp này, chúng ta cần tìm điểm Z-score tương ứng cho xác suất hoặc phần trăm đã cho.
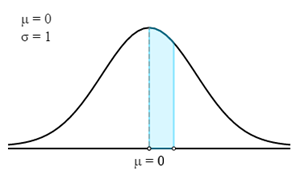
Để tìm Điểm Z, chúng ta cần tìm xác suất trong vùng được highlight.
Chúng ta có thể tính được bằng cách trừ 0,50 cho 0,30. Do đó, xác suất của vùng được đánh dấu (highlight) là 0,20.
Bây giờ, trong bảng Z, chúng ta cần tìm xác suất gần nhất với 0,20. Điểm Z tương ứng là 0,524.
Sau đó, chúng ta cần tìm giá trị X bằng công thức Z-Score.
- Z = (X - μ)/σ
- 0.524 = (X - 55)/10
- X = (0,524 × 10) + 55
- X = 60,24
Vì vậy, điểm đậu tối thiểu cho kỳ thi là 60,24.